


What Is a Large Language Model? (Explained Simply)
100 million people in India use ChatGPT every week. Most of them have no idea what is actually running under the hood.
That is not a criticism. Nobody told them. Every explainer on the internet either skips straight to transformer architecture or treats readers like they already have a CS degree. Neither helps a normal person understand what is actually happening when they type a question and an AI answers it.
So here is a plain-English explanation. A large language model (LLM) is an AI system trained on enormous amounts of text that predicts what word should come next, billions of times, until it becomes very good at generating human-like responses. That is the core of it. Everything else, the apparent intelligence, the hallucinations, the context windows, follows from that one idea.
I will walk through what LLMs are, how they work, what real examples exist, where they fail, and where they are heading. No math required.
What Is a Large Language Model, Really?
A large language model is an AI system that learns to understand and generate human language by studying patterns across massive amounts of text. AWS defines LLMs as "very large deep learning models that are pre-trained on vast amounts of data." That is technically correct. Here is what it actually means.
Think of it like this. Imagine you read every book, every website, every Reddit thread, every news article ever written. Then someone asked you: "Given these words, what comes next?" Over time, you would get very good at predicting language patterns. You would understand context, tone, grammar, and subtle relationships between ideas.
That is what an LLM does, except at a scale no human could match. GPT-4 from OpenAI was trained on roughly 45 terabytes of text. Claude from Anthropic was trained on trillions of tokens from the public internet, books, and code. The model does not know things the way you know your own name. It has learned statistical patterns at a scale that produces something that looks, and often feels, like genuine understanding.
My honest take: calling it "intelligence" is probably too strong, and calling it "just autocomplete" is too dismissive. The truth sits somewhere in between, and it is genuinely impressive wherever you land on that spectrum.
What Does "Large" Actually Mean?
The "large" in large language model refers to the number of parameters the model has. Parameters are numerical values the model adjusts during training, essentially the knobs it tunes to get better at predicting text.
For context, here is what scale looks like in 2026:
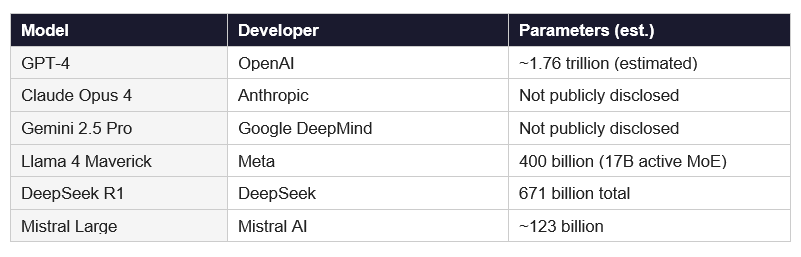
More parameters generally means more capacity to learn complex patterns. But raw size is not everything. DeepSeek R1, released in January 2025, matched or outperformed GPT-4 on many benchmarks while costing a fraction as much to run, because it uses a smarter architecture called Mixture of Experts (MoE) that activates only a subset of parameters at once.
The race is no longer just about who has the most parameters. It is about who can do the most with the fewest active ones. That is the part most explainers skip.
How LLMs Work: Tokens, Training, and Next-Word Prediction
LLMs work by breaking text into tokens, learning patterns across trillions of those tokens during training, and then generating responses by predicting the most likely next token at each step. Here is how each piece fits together.
Step 1: Tokenization
Before an LLM reads any text, it breaks that text into tokens. A token is not exactly a word. It is a chunk of text, anywhere from a single character to a full word or common phrase.
For example, the word "unhappiness" might be split into three tokens: "un", "happi", and "ness". OpenAI's GPT-4 uses a vocabulary of about 100,000 unique tokens. On average, one token represents about 0.75 words in English. A 1,000-word essay is roughly 1,333 tokens.
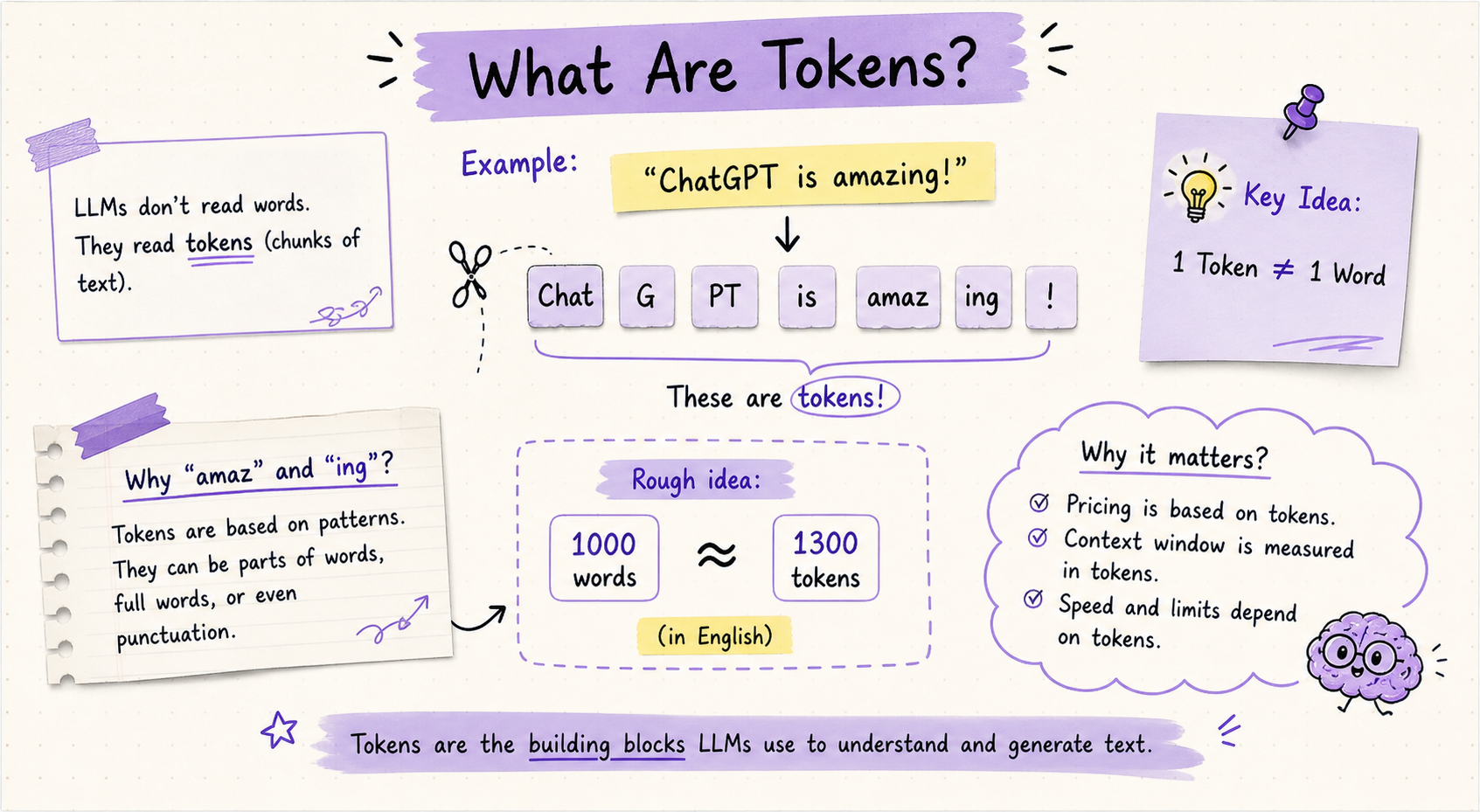
Why does this matter? Because everything about LLM pricing, context windows, and speed is measured in tokens, not words. When ChatGPT says you have hit your context limit, it means you have used up the maximum number of tokens the model can hold in memory at once.
Step 2: Pre-Training
During pre-training, the model reads trillions of tokens and learns to predict the next token in a sequence. Each time it makes a prediction, it checks whether it was right and adjusts its parameters to do better next time.
This process runs across thousands of GPUs for weeks or months. OpenAI, Google, and Anthropic each spend tens of millions of dollars on a single pre-training run. The output is a "base model" that is very good at predicting language but has not yet been trained to be helpful or safe in conversation.
Step 3: Fine-Tuning and RLHF
After pre-training, the model goes through fine-tuning. Human trainers rate different model responses for helpfulness, accuracy, and safety. The model learns from these ratings through a technique called Reinforcement Learning from Human Feedback (RLHF).
This is what transforms a raw language predictor into something like ChatGPT or Claude. The model learns not just to predict text, but to generate responses humans prefer. RLHF is why Claude sounds thoughtful and why ChatGPT follows instructions rather than just completing whatever sentence you started.
Step 4: Inference (When You Use It)
When you type a message to any AI chatbot, the model takes your input as tokens and generates a response one token at a time, each token chosen based on probability. The response is not retrieved from a database. It is generated fresh, every single time, token by token, based on everything the model learned during training.
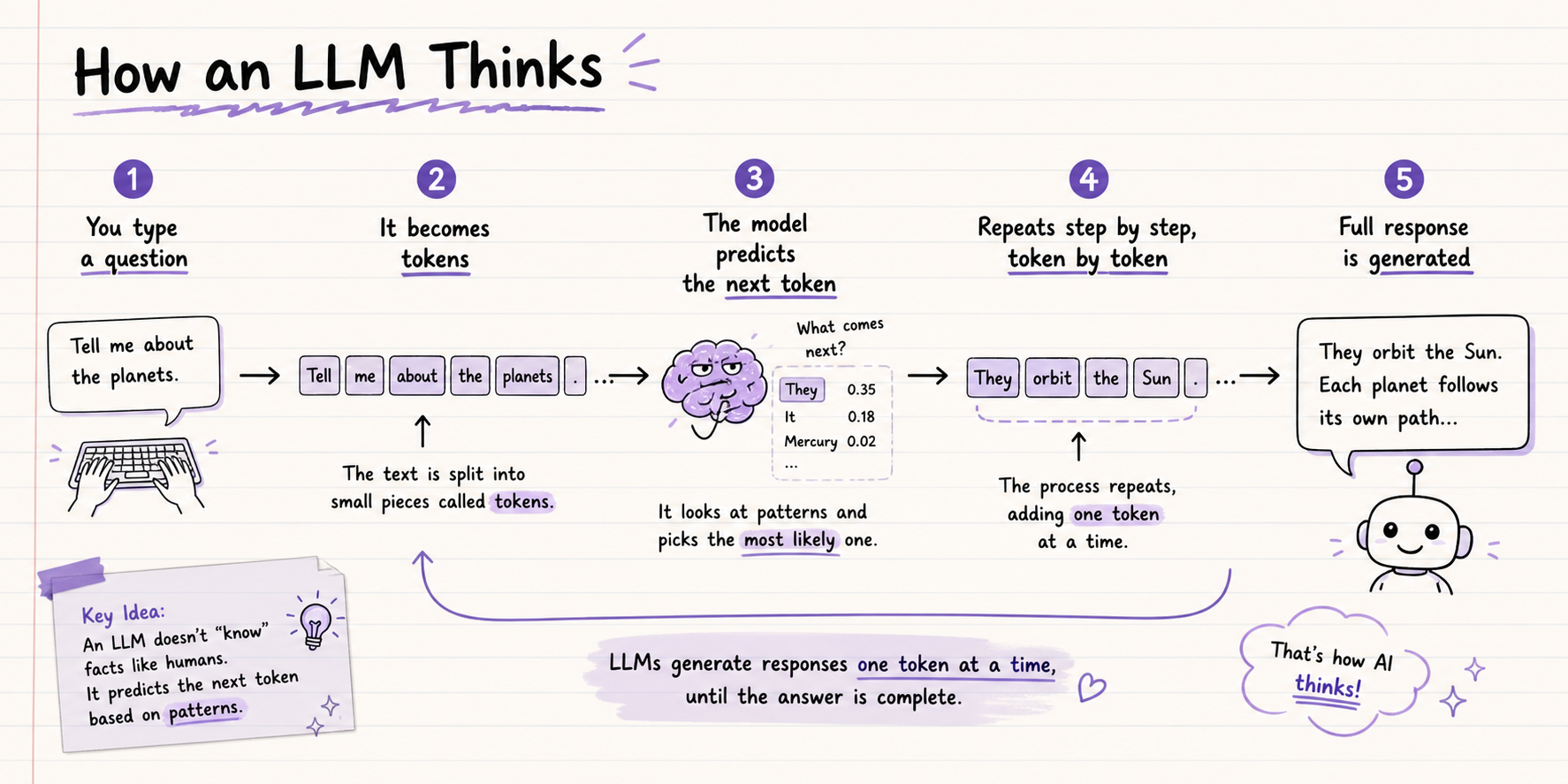
This is also why LLMs can sound so confident while being completely wrong. They generate the most statistically likely next token, not the most factually accurate one.
Real-World Examples of LLMs in 2026
The LLM landscape in 2026 is crowded. Here are the main models any beginner should know:
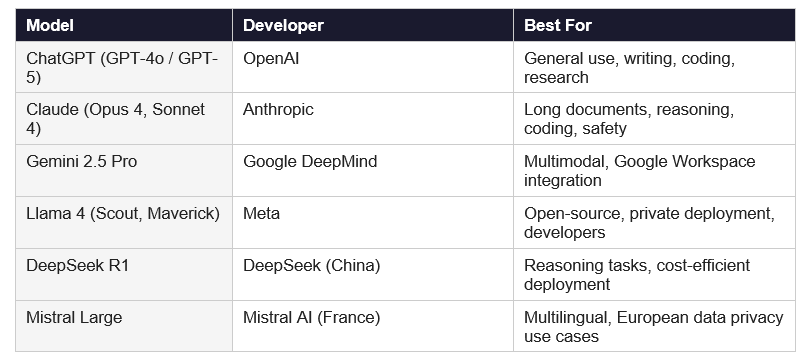
A quick note on open-source: Llama 4 from Meta is fully downloadable and runnable on your own hardware. This matters enormously for privacy, cost, and customization. If your company cannot send data to OpenAI for legal reasons, Llama is often the answer.
Contrarian take: the model you use matters less than most people think. For everyday tasks, the difference between GPT-4o and Claude Sonnet 4 is smaller than the difference between a good prompt and a bad one. Learn to write better prompts first, then worry about which model.
What Can LLMs Do?
LLMs handle a surprisingly wide range of tasks. Here is what they are genuinely useful for right now:
Writing: drafting emails, blog posts, reports, product descriptions, and social media copy
Coding: writing, explaining, and debugging code in Python, JavaScript, SQL, and most other languages
Summarization: condensing long documents, research papers, or meeting transcripts into key points
Translation: converting text across 100+ languages with near-human fluency in major pairs
Customer support: powering chatbots that handle common questions without human intervention
Research: searching the web, synthesizing information, and generating structured summaries
Education: explaining complex topics at different difficulty levels, acting as a personal tutor
Data analysis: reading CSV files, identifying patterns, and writing SQL or Python to analyze datasets
What LLMs cannot do reliably: anything requiring real-time information (unless given web search access), physical actions in the real world, guaranteed factual accuracy, or long-term memory across separate conversations.
I use LLMs every day for first drafts, code review, and research synthesis. I do not use them as my final source of truth on anything important. That distinction matters a lot.
LLMs vs Traditional Software: What Changed
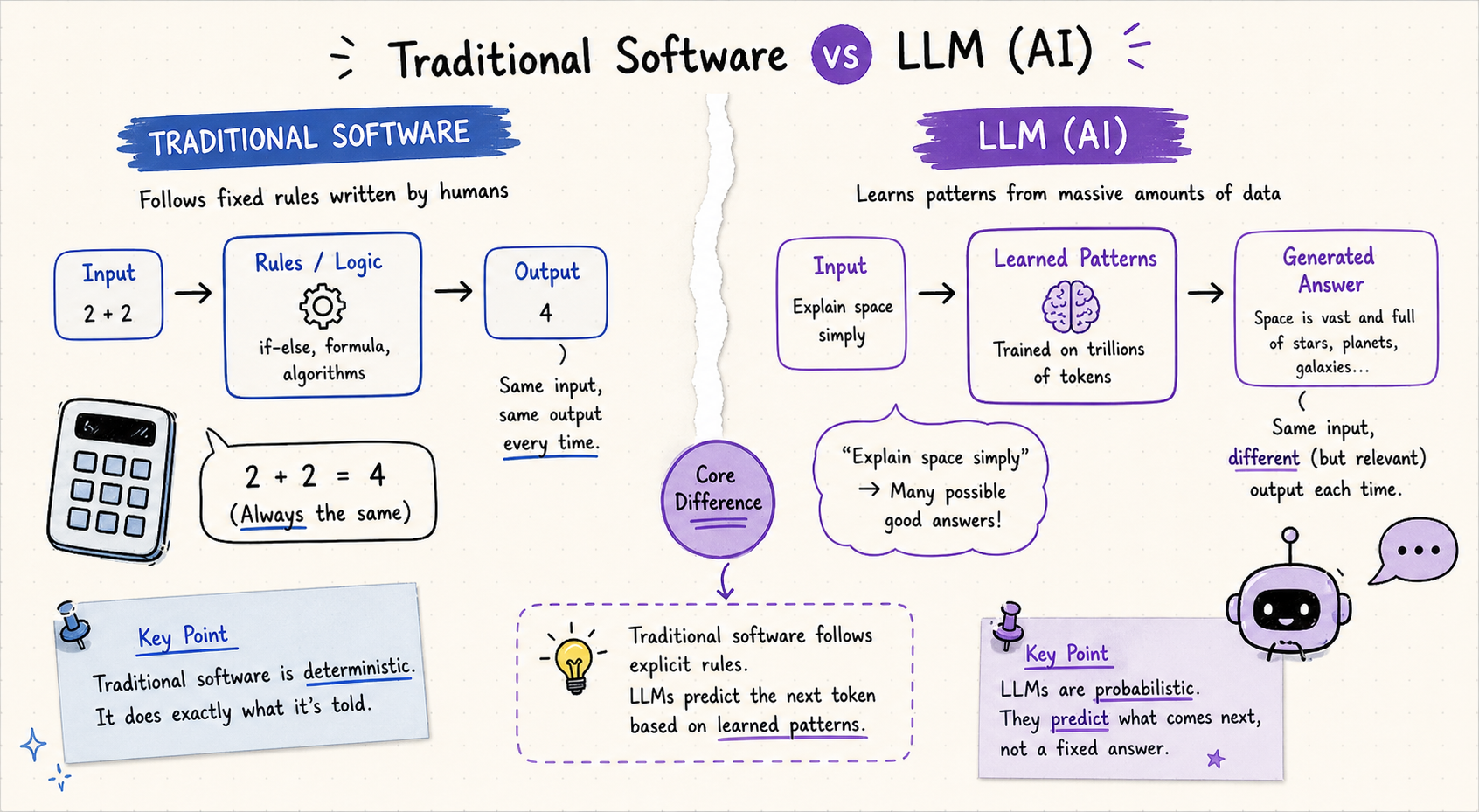
Traditional software follows explicit rules written by programmers. An LLM learns patterns from data. This sounds like a small difference. The practical gap is enormous.
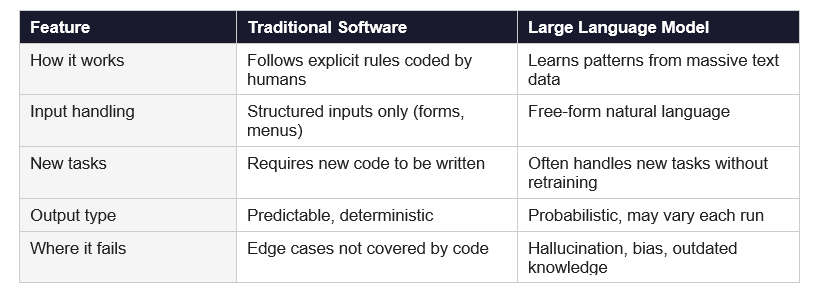
The reason LLMs feel different from every software product you have used before is that they are genuinely not rule-based. A calculator will always give you the same answer for 2+2. An LLM might give you a slightly different phrasing each time, and on a complex question, might occasionally give you the wrong answer entirely.
That unpredictability is both what makes LLMs powerful (they handle situations no programmer explicitly anticipated) and what makes them risky (they can confidently generate false information).
Where LLMs Get It Wrong
LLMs have real, well-documented limitations. Anyone using them regularly needs to understand these:
Hallucination
AI hallucination is when a model generates confident-sounding but factually incorrect information. It happens because LLMs predict statistically likely text, not verified facts. In 2022, a ChatGPT response invented fake legal citations that were submitted to a US federal court. The lawyer did not check them. That is the risk in practice.
The solution is not to stop using LLMs. It is to verify any specific fact, citation, or number before relying on it.
Outdated Knowledge
Every LLM has a training cutoff, the date after which it has no knowledge of events. If you ask about something that happened after that date without giving the model web search access, it will either admit it does not know or, worse, guess.
Context Window Limits
Every LLM can only "see" a certain number of tokens at once. This is called the context window. Claude Opus 4 supports up to 200,000 tokens (roughly 150,000 words). Meta's Llama 4 Scout has a 10 million token context window. GPT-4o supports 128,000 tokens.
If your document or conversation exceeds the context window, the model forgets the earlier parts. This is why very long ChatGPT conversations sometimes produce answers that feel disconnected from what you said at the start.
Bias
LLMs are trained on internet text, which reflects the biases present in human writing. Models can reproduce stereotypes, favor certain perspectives, or handle different languages with different fluency levels. Every major AI lab works on reducing bias, but none have eliminated it.
The Future of LLMs
The LLM space is moving faster than almost any technology in history. Here is where things are heading:
AI agents: LLMs that do not just answer questions but take actions, browse the web, write and run code, and complete multi-step tasks. Claude Opus 4 from Anthropic is built specifically for agentic workflows.
Multimodal models: LLMs that handle images, audio, and video alongside text. Gemini 2.5 Pro processes text, images, audio, video, and code. GPT-5 does the same.
Smaller, faster models: Mistral Small 3.1 runs on a single consumer GPU at 150 tokens per second. On-device LLMs running locally on your phone are already here.
Open-source closing the gap: Meta's Llama 4 Maverick outperforms GPT-4o on several benchmarks. The gap between proprietary and open models is the smallest it has ever been.
Personalized AI: models that remember your preferences, writing style, and context across sessions. This is the next major shift after raw capability improvements.
My read on this: the "what is an LLM" question will feel quaint within two years. We will stop talking about LLMs as a category and start talking about what AI agents actually built or decided for us. The model is becoming infrastructure, not the product.
Frequently Asked Questions
Q: What is a large language model in simple terms?
A large language model is an AI system trained on billions of words of text that learns to predict and generate human language. When you type a question into ChatGPT or Claude, the model generates a response one token at a time, based on patterns it learned during training. LLMs do not look up answers in a database. They generate them fresh every time.
Q: Is ChatGPT an LLM?
Yes. ChatGPT is an AI chatbot built on top of GPT-4o and GPT-5, which are large language models developed by OpenAI. The LLM is the underlying model. ChatGPT is the product interface built on top of it. Similarly, Claude is the interface and claude-opus-4 is the LLM powering it.
Q: What is the difference between LLM and generative AI?
Generative AI is the broader category of AI systems that generate new content including text, images, audio, and video. LLMs are a specific type of generative AI focused on text and language. ChatGPT and Claude are LLMs. DALL-E and Midjourney are image generators. Both are generative AI, but only LLMs are language models.
Q: What is a token in AI?
A token is the smallest unit of text an LLM processes. Tokens are chunks of text ranging from a single character to a full word or common phrase. In English, one token is roughly 0.75 words on average. OpenAI's GPT-4 uses a vocabulary of about 100,000 unique tokens. All LLM pricing, context limits, and speed are measured in tokens, not words.
Q: What is a context window in an LLM?
The context window is the maximum number of tokens an LLM can process in a single conversation or request. Claude Opus 4 has a 200,000-token context window (about 150,000 words). Meta's Llama 4 Scout supports up to 10 million tokens. GPT-4o supports 128,000 tokens. If your conversation exceeds the context window, the model starts to forget earlier parts.
Q: Why do LLMs hallucinate?
LLMs hallucinate because they generate statistically probable text rather than verified facts. The model predicts what word should come next based on training patterns, and sometimes those patterns produce confident-sounding text that is factually wrong. Hallucination is an inherent feature of probabilistic text generation. Always verify specific facts, citations, and numbers from LLM outputs before relying on them.
Q: What are examples of large language models?
The most widely used LLMs in 2026 are GPT-4o and GPT-5 from OpenAI, Claude Opus 4 and Sonnet 4 from Anthropic, Gemini 2.5 Pro from Google DeepMind, Llama 4 from Meta, DeepSeek R1 from DeepSeek, and Mistral Large from Mistral AI. Each has different strengths, pricing, and context window sizes.
Q: What is the difference between AI and LLM?
AI (artificial intelligence) is a broad field covering any system that mimics human-like problem solving. LLMs are a specific subset of AI focused on understanding and generating language. Machine learning, computer vision, and robotics are all forms of AI that are not LLMs. LLMs are AI, but not all AI is an LLM.
Recommended Blogs
If this sparked some curiosity, these reads are worth your time next:
• How to Learn AI From Scratch in 2026
Start Learning AI in 5 Minutes a Day
The best way to actually understand LLMs is to use them. Not study them. Use them. Most people fail at AI because they read about it instead of building with it.
Unrot teaches AI in five minutes a day. No jargon, no math, just the concepts that matter, one day at a time.
References
1. AWS -- What Is a Large Language Model?
2. Google Cloud -- Large Language Models (LLMs)
3. IBM -- What Are Large Language Models?
4. Cloudflare -- What Is an LLM?
5. Wikipedia -- Large Language Model
6. Microsoft Learn -- Understanding Tokens
7. Google for Developers -- LLMs and Transformers

