


How Are AI Models Trained? A Beginner's Guide with No Math
ChatGPT learned to write emails, explain diseases, and argue philosophy by playing one game, billions of times over: guess the next word.
That is not a simplification. It is the literal mechanism. A language model is trained to predict which word (technically, which token) is most likely to come next in any sequence of text. Do that across 15-20 trillion tokens of human writing — books, articles, research papers, code, conversations — and something extraordinary emerges from the pattern-matching: a system that appears to reason, write, explain, and create.
Most AI explainers either stay too vague ('the model learns from data') or go too deep ('gradient descent via backpropagation through transformer attention layers'). This post goes somewhere in between. You will understand the actual 4-step process that takes an AI model from nothing to the assistant answering your questions — with analogies that make it real, and numbers that make it concrete. No equations. No code. Just the honest picture.
The Simple Analogy: What Training Actually Is
Before the steps, let me give you the mental model that makes everything else click.
Imagine a new employee on their first day. They are brilliant — went to university, read widely, understand language perfectly — but they have never worked at your company.
Their training happens in two phases:
Phase 1 — General education: They spend years reading everything they can find about the world. History, science, technology, law, cooking, poetry. They become extraordinarily knowledgeable about how the world works and how language is used to describe it. But they have no specific skills and no idea what 'good work' looks like at your company.
Phase 2 — Company training: They join your team. Senior colleagues show them examples of excellent work. They practise. Managers give them feedback: 'That response was helpful.' 'That one was vague — try again.' Over time, their behaviour aligns with what your company considers good.
That is AI training. Phase 1 is pre-training. Phase 2 is RLHF (Reinforcement Learning from Human Feedback). The 'general education' phase creates capability. The 'company training' phase creates usability.
One key difference from the human analogy: the AI employee does not understand any of this in the way a human would. They do not have experiences, opinions, or consciousness. They have statistical patterns — extremely sophisticated ones, learned across an unfathomably large amount of text. But patterns all the same. This distinction matters because it explains why AI sometimes sounds confident while being completely wrong: it is predicting what sounds right, not verifying what is right.
STEP 1: Collecting the Training Data
Before any training begins, someone has to gather the data the model will learn from. For a frontier model like GPT-5.5 or Claude Opus 4.7, that dataset is enormous — modern pre-training datasets now exceed 15-20 trillion tokens, according to AI research published in early 2026.
What goes into a frontier model's training data:
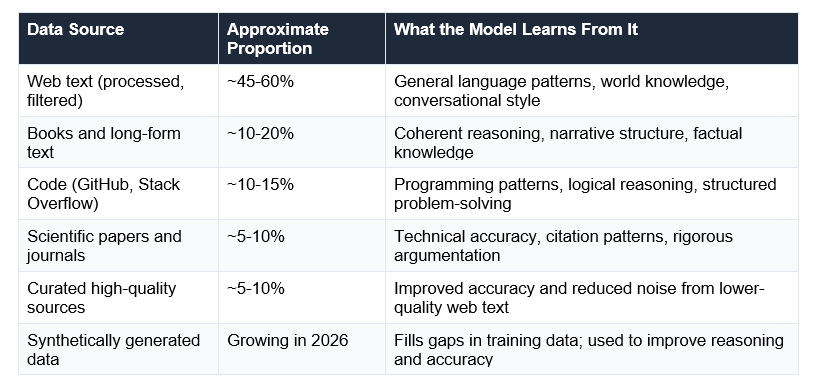
Data quality matters enormously — and this is underappreciated. A model trained on 5 trillion high-quality, curated tokens consistently outperforms a model trained on 15 trillion low-quality scraped web tokens on tasks requiring accuracy, reasoning, and factual precision. In 2026, the biggest training data shift is the move toward synthetic data generation — using existing AI to create new training examples that fill specific capability gaps.
One critical property of training data: everything is unlabelled. There is no teacher marking correct answers. There is no 'this sentence is true, that sentence is false.' The supervision signal comes entirely from the structure of the text itself — from predicting what word comes next
STEP 2: Tokenisation — How AI Actually Reads Text
Here is something counterintuitive: language models do not read words. They read tokens.
A token is roughly three-quarters of a word in English — approximately 4 characters. Before training begins (and before every inference), text is broken into these chunks through a process called tokenisation. The word 'understanding' is typically one token. 'ChatGPT' is one token. A space at the start of a word is often a separate token.
Concrete example: The sentence 'How are AI models trained?' might be tokenised as: ['How', ' are', ' AI', ' models', ' trained', '?'] — 6 tokens. OpenAI's tiktoken tokeniser breaks text into these sub-word units using Byte-Pair Encoding (BPE), which learns the most common groupings of characters from training data.
Why tokenise instead of using full words? Three reasons:
Handles any language: Tokenisation works on characters, so the model can process any language, any dialect, any new word, without needing a fixed dictionary.
Manages vocabulary size: A fixed word vocabulary would need to include every word in every language. Token vocabularies are more manageable — GPT-4 uses 100,000 tokens.
Captures meaning at sub-word level: 'unhelpful', 'unhappy', 'unlucky' share the 'un-' prefix. Tokenisation captures these shared patterns, helping the model learn morphology without explicit rules.
This is also why AI pricing is measured in tokens and why context windows are measured in tokens. Every word you type costs roughly 1.33 tokens. Every response the model generates costs roughly 1.33 tokens per word. 1,000 words ≈ 1,333 tokens.
STEP 3: Pre-Training — The 'Guess the Next Word' Game at Scale
This is the heart of it. Pre-training is where the model develops its capabilities — its ability to reason, write, code, explain, and translate. And it all happens through one deceptively simple task:
Given all the text that came before, predict the next token.
That is it. The model sees 'The capital of France is' and has to predict 'Paris'. It sees 'def calculate_area(radius):' and has to predict 'return'. It sees a half-finished sentence in Mandarin and has to predict the next character.
The training loop runs like this, billions of times:
The model receives a sequence of tokens from the training data.
It predicts the probability distribution for what comes next — essentially ranking every token in its vocabulary by likelihood.
The actual next token (which exists in the training data) is revealed.
The gap between what the model predicted and what actually came next is calculated — this gap is the 'loss.
The model's internal parameters (hundreds of billions of numbers called 'weights') are adjusted slightly to reduce this gap.
Repeat. Billions of times. Across trillions of tokens.
What makes this work is something that feels almost magical: to predict the next word well, you have to understand a huge amount about how the world works. To predict what follows 'The patient was diagnosed with' requires knowledge of medicine. To predict what follows 'The function returned the wrong value because' requires knowledge of programming logic. The model was never told these things. It inferred them from patterns across trillions of examples.
The architecture that makes this possible is the transformer, introduced in a landmark 2017 Google paper 'Attention Is All You Need.' Transformers use a mechanism called attention that lets the model understand relationships between all tokens in a sequence simultaneously — rather than reading word by word. This is why GPT stands for Generative Pre-trained Transformer.
Scale in numbers: GPT-4 reportedly trained on approximately 13 trillion tokens using 10,000+ NVIDIA A100 GPUs running continuously for approximately 100 days. The model developed roughly 1.76 trillion parameters — individual numerical weights — that together encode its learned understanding of language, facts, and reasoning
STEP 4: RLHF — Learning from Human Feedback
At the end of pre-training, the model is impressively capable but deeply unreliable as an assistant. It knows an enormous amount about the world. But it has no idea what 'being helpful' means. Left to its own devices, a raw pre-trained model might complete your sentence by continuing with something statistically plausible from the internet — which could be harmful, misleading, offensive, or just unhelpful.
RLHF (Reinforcement Learning from Human Feedback) is the stage that transforms this raw, capable-but-erratic system into the assistant you actually interact with.
Phase A: Supervised Fine-Tuning (SFT)
Human trainers write examples of ideal conversations — good prompts paired with good responses. These examples teach the model the format of being a helpful assistant: how to structure an answer, how to handle ambiguous questions, how to be concise. Anthropic's early Claude training used approximately 300,000 such examples, according to published research.
Phase B: Reward Model Training
The model is given the same prompt multiple times and generates several different responses. Human annotators then compare pairs of responses and rank them: 'Response A is better than Response B.' These preference rankings train a separate reward model — a system that learns to score any response on a scale of helpfulness, accuracy, and safety. A typical training run uses 50,000 to 500,000 such comparison pairs.
Phase C: Reinforcement Learning
The main language model is then fine-tuned using reinforcement learning — specifically, an algorithm called PPO (Proximal Policy Optimisation). The model generates responses, the reward model scores them, and the language model's weights are adjusted to produce higher-scoring responses more often. This loop runs thousands of times until the model's behaviour converges toward consistently helpful, accurate, and safe outputs.
The most striking result from RLHF research: A 1.3-billion parameter model fine-tuned with RLHF outperforms a 175-billion parameter base model on human preference evaluations — according to OpenAI's 2022 InstructGPT paper. The model trained with human feedback was 100x smaller but significantly more useful. Size matters, but alignment matters more.
RLHF is why ChatGPT declines harmful requests, Claude discusses sensitive topics carefully, and Gemini tries to be balanced. It is not because these behaviours were hand-coded as rules. It is because humans indicated they preferred these behaviours, and the reward model learned to score them highly, and the language model learned to produce them.
By 2026, approximately 70% of enterprise LLM deployments use some variant of RLHF or its successors — DPO (Direct Preference Optimisation) and GRPO — for alignment, according to research cited by DecodetheFuture.
How Long Does Training Actually Take?
The answer depends enormously on what you're training:
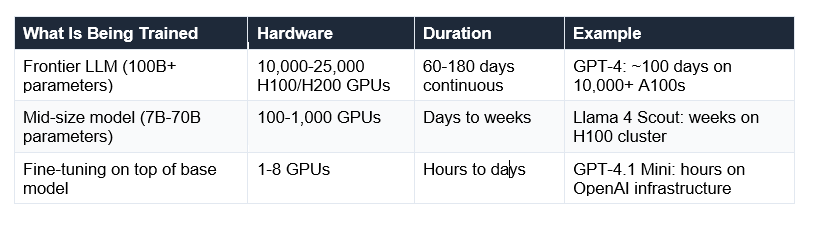
GPT-4's training is estimated to have required approximately 21 billion petaFLOPS of computational work, according to Stanford's AI Index Report. To put that in context: one petaFLOP is one quadrillion floating-point operations per second. Running that on a modern gaming PC would take approximately 700 years. On 10,000 H100 GPUs, it took around 100 days.
Why Training Is So Expensive
The cost of training frontier AI models has become one of the defining economic realities of the AI industry. Here are the specific numbers:
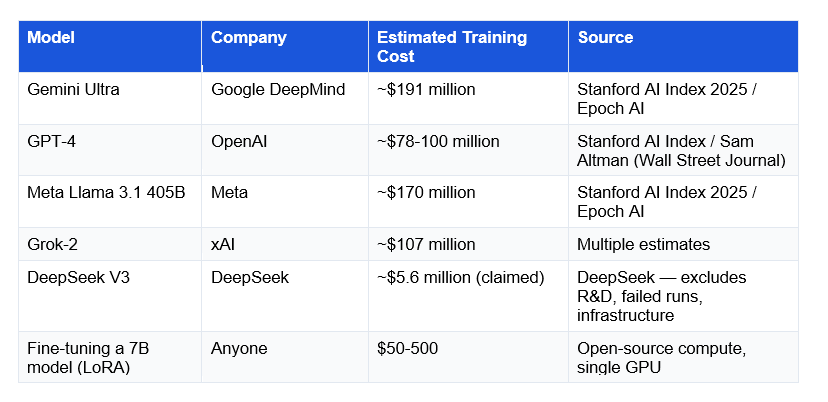
The cost breakdown for a frontier training run:
GPU compute (60-70%): 10,000-25,000 high-end GPUs at ~$25,000 per H100 purchase price, or $1-8/hour on cloud. GPT-4 used 10,000+ A100s for approximately 100 days — at marketplace rates, that's $24M+ in compute alone, before overhead.
Data preparation (10-15%): Acquiring, filtering, cleaning, and formatting 15-20 trillion tokens of text. This step is undervalued — data quality determines model quality more than model size.
Engineering personnel (15-20%): The teams of ML engineers, researchers, and safety specialists who design, monitor, debug, and evaluate training runs.
Infrastructure overhead (5-10%): Power consumption (gigawatt-hours of electricity), networking between GPUs, storage, and cooling. A 100-day training run on 10,000 GPUs consumes enough electricity to power thousands of homes.
Important context: Training costs have grown 2-3x per year for eight years according to Epoch AI, but cost-per-unit of compute drops approximately 10x annually due to hardware and algorithmic efficiency improvements. DeepSeek's claimed $5.6M training cost demonstrates that algorithmic efficiency (MoE architecture, sparse training) can dramatically reduce costs — even if the real number is higher than stated.
What Happens After Training?
After pre-training and RLHF, the model is frozen — its weights are fixed. This frozen version is called a base model or foundation model. From here, three things happen:
Inference deployment
The trained model is deployed on servers so users can query it. Each query you send to ChatGPT, Claude, or Gemini runs inference — the model uses its frozen weights to generate a response. Training changes the weights; inference uses them. Inference is far cheaper than training but adds up at scale: OpenAI handles millions of requests per day.
Continuous evaluation and safety testing
Before and after deployment, AI companies run extensive evaluations — testing the model on thousands of prompts covering accuracy, safety, bias, and capability. Anthropic's red team specifically tries to get Claude to produce harmful outputs. OpenAI offers up to $300,000 in bug bounties to researchers who find security vulnerabilities in GPT models.
Next model training begins
In 2026, AI companies are often training the next model before the current one is deployed. The pace is roughly one major frontier model update every 6-12 months per company — with smaller iterative updates more frequently. Each new model builds on insights from the previous one: better architecture choices, better training data curation, better alignment techniques.
The training vs inference distinction matters practically: a model's knowledge is fixed at training time. Anything that happened after its training cutoff is unknown to the model — which is why ChatGPT and Claude cannot answer questions about last week's news without a web search tool. The model cannot learn new facts after training; it can only use what it learned during those months of pre-training.
Frequently Asked Questions
Q: How are AI models trained in simple terms?
AI model training happens in two major phases. Pre-training: the model reads trillions of tokens of text and learns to predict what word comes next, billions of times. Through this process it develops a statistical understanding of language, facts, and reasoning. RLHF (Reinforcement Learning from Human Feedback): human trainers show the model examples of helpful responses and rank which outputs they prefer. The model learns to produce the kinds of outputs humans rate highly — becoming helpful, safe, and coherent rather than just statistically plausible.
Q: How is ChatGPT trained?
ChatGPT is trained in four stages. First, massive amounts of internet text, books, and code are collected and cleaned. Second, the text is tokenised — broken into sub-word units the model processes. Third, pre-training: GPT-4 was trained on approximately 13 trillion tokens using 10,000+ NVIDIA A100 GPUs for approximately 100 days, learning to predict the next token. Fourth, RLHF: human trainers rank response quality, a reward model learns to score helpfulness and safety, and reinforcement learning aligns the model's outputs toward human-preferred behaviour.
Q: What data is AI trained on?
Frontier AI models like GPT-5.5 and Claude Opus 4.7 are trained on datasets exceeding 15-20 trillion tokens. The data typically includes: filtered web text (45-60%), books and long-form content (10-20%), code from GitHub and Stack Overflow (10-15%), scientific papers (5-10%), and curated high-quality sources. In 2026, synthetically generated data is increasingly used to fill capability gaps. Everything is unlabelled — there is no teacher marking right and wrong answers. The supervision signal comes from predicting the next token.
Q: How long does it take to train an AI model?
It depends enormously on scale. Frontier models (100B+ parameters) take 60-180 days on 10,000-25,000 GPUs running continuously. GPT-4 reportedly took approximately 100 days on 10,000+ A100 GPUs. Mid-size models (7B-70B parameters) take days to weeks. Fine-tuning a pre-trained model with LoRA on a single consumer GPU can take 7-48 hours. The time is determined by the number of parameters, the size of the training dataset, and the number of GPUs available.
Q: Why does training AI cost so much money?
Three main factors: GPU infrastructure (60-70% of cost) — training GPT-4 required 10,000+ NVIDIA A100 GPUs for ~100 days, costing $78-100M according to Stanford AI Index research. Data preparation (10-15%) — acquiring, cleaning, and curating 15-20 trillion tokens is a significant engineering effort. Engineering personnel (15-20%) — teams of ML researchers and safety engineers who design and monitor training runs. Gemini Ultra's training is estimated at $191M; frontier models are now heading toward $1B+ per training run, with AI companies projecting $5-10B training runs by 2026-2027.
Q: What is RLHF and why does it matter?
RLHF stands for Reinforcement Learning from Human Feedback. It is the training stage that transforms a raw pre-trained model — capable but unreliable — into a helpful assistant. Human trainers rank pairs of model responses by quality and safety. A reward model learns to score responses automatically. Reinforcement learning then adjusts the main model toward producing higher-scored responses. RLHF is why ChatGPT follows instructions, Claude declines harmful requests, and Gemini tries to be balanced. A striking result: a 1.3B parameter RLHF-trained model outperforms a 175B base model on human preference evaluations (OpenAI InstructGPT, 2022).
Q: What is the difference between training and inference in AI?
Training is the process of teaching the model — adjusting its billions of parameters by running it across massive datasets. It is expensive, slow, and happens before deployment. Inference is using the trained model — sending a query and receiving a response. Each response you get from ChatGPT or Claude is inference. Inference is much cheaper than training, but the model's knowledge is frozen at training time. Inference cannot update what the model knows — which is why AI models have knowledge cutoff dates and cannot learn from your conversations (unless explicitly designed to do so).
Q: What are AI model parameters?
Parameters are the billions of numerical weights inside a neural network that encode everything the model has learned. During training, these weights are adjusted millions of times until the model can predict text accurately. During inference, they are frozen — the model uses them to generate responses but does not change them. GPT-4 reportedly has approximately 1.76 trillion parameters. Claude Opus 4.7 and Gemini 3.1 Pro have not disclosed exact parameter counts. More parameters generally mean more capacity to learn complex patterns, but efficient training and better data increasingly matter more than raw parameter count.
Understanding how AI is trained changes how you use it — and how much you trust it.
The Unrot course 'How LLMs Work' goes deeper on transformers, attention, and why the training process explains so many of AI's quirks — in 5 minutes, no math. Free in the app.
app.unrot.co → Beginner Path → How LLMs Work
References
Published on Unrot.co | May 2026

