


What ChatGPT Actually Sees
You type: "Can you write a short email declining a meeting?" ChatGPT doesn't see those words the way you do. It never has.
Before a single character of your text reaches the model, it gets shredded. Cut up. Converted into a sequence of numbers that look nothing like English. Each piece of that sequence is called a token.
GPT-4o doesn't read. It calculates. Specifically, it predicts the next most probable number in a sequence, over and over, until the response is complete. Understanding that mechanic is the single most useful thing you can learn about how AI actually works.
I'll be honest: when I first learned this, it changed how I use ChatGPT. Once you see text the way the model sees it, you write better prompts, hit fewer limits, and stop being confused about why AI sometimes stumbles on simple tasks.
What Is a Token in AI? (Simple Definition with Examples)
A token is the smallest unit of text that a large language model (LLM) processes. It can be a full word, part of a word, a punctuation mark, or even a single character. When you send text to an AI model, a tokenizer splits that text into tokens, converts each token to a unique number, and passes those numbers to the model.
Here is the clearest way to think about it: if AI is a calculator, tokens are the digits.
Three concrete examples to make this real:
Short common word: "cat" = 1 token. Simple, common, whole word.
Long or rare word: "tokenization" = 3 tokens: "token" + "iz" + "ation". Rare words get split.
Punctuation and spaces: " is" (space+is) = 1 token. " great!" = 2 tokens. Even spaces count.
The rule of thumb OpenAI uses: roughly 1 token = 0.75 English words, or about 4 characters. So 100 tokens is approximately 75 words of typical English text. In practice, this varies significantly by language, code, and special characters.
Quick Stat
GPT-4's tokenizer (cl100k_base) supports 100,277 unique token IDs. GPT-4o's tokenizer (o200k_base) supports 200,019. The larger vocabulary means fewer tokens for the same text, which means lower cost and better efficiency.
My take: The token-based system is not a quirk or a limitation. It is one of the reasons LLMs are so powerful. By working at the subword level, models can handle words they have never seen before by breaking them into known parts. The downside is that rare words, non-English text, and code often use more tokens than you'd expect.
How Tokenization Works: The BPE Algorithm
The tokenization algorithm used by OpenAI's models is called Byte Pair Encoding (BPE). It was originally a data compression algorithm. Researchers adapted it for language models in 2016, and it became the backbone of GPT tokenization.
Here is how BPE works, step by step:
Start with every character as its own token (a, b, c, d, ...)
Count which pairs of tokens appear most often in your training data
Merge the most frequent pair into a new token (e.g., "th" merges because it is extremely common in English)
Repeat millions of times until you reach the target vocabulary size
The result is a vocabulary where common words or syllables become single tokens, and rare words get broken into smaller pieces. The word "running" might become ["run", "ning"] or just ["running"] depending on how common it was in training data.
Why Not Just Use Words?
Word-level tokenization has a fatal problem: out-of-vocabulary words. A model trained on English has no token for "cryptocurrency" if it was never in training data. BPE solves this by breaking it into known parts: ["crypto", "currency"] or ["crypt", "ocurr", "ency"]. The model can handle any new word through its components.
Character-level tokenization (one token per letter) would solve that problem but creates a different one: sequences become extremely long. The word "internationalization" at the character level is 20 tokens. At the BPE subword level, it is 4-6 tokens. Shorter sequences = less computation = lower cost = faster response.
Input Tokens vs. Output Tokens: The Difference That Costs You Money
When you use any AI model through an API, you pay for two buckets of tokens, and they are priced differently.

Output tokens are 4x more expensive than input tokens on GPT-4o (as of May 2026). This is not arbitrary. Generating text requires much more computation than reading it. The model needs to run a full forward pass for every single output token it generates.
Practical implication: if you ask a model for a 1,000-word essay, you pay for every word of output at the higher rate. Asking for summaries instead of full drafts, or using cheaper models for output-heavy tasks, can cut your AI bill dramatically.
What Is Tiktoken? OpenAI's Official Tokenizer
Tiktoken is OpenAI's open-source Python library for tokenizing text using the exact same byte-pair encoding that their models use. It was developed by Shantanu Jain at OpenAI and first released in 2022. It is available on PyPI (pip install tiktoken) and GitHub (github.com/openai/tiktoken).
The key feature: when you tokenize text locally using tiktoken, you get the exact same token counts that the OpenAI API will charge you for. No guessing. No approximation. The same BPE implementation, the same vocabulary, the same numbers.
Why was tiktoken built? Before tiktoken, developers used rough formulas (divide word count by 0.75) to estimate tokens. This led to surprises when prompts hit context limits mid-conversation or when invoices came in higher than expected. Tiktoken eliminated the guessing.
Performance: tiktoken is implemented in Rust and called from Python. OpenAI reports it is 3-6x faster than comparable open-source tokenizers like HuggingFace's tokenizers library. For production systems processing millions of tokens, that speed matters.
Tiktoken vs. Other Tokenizers
HuggingFace's tokenizers library also supports BPE and is widely used for open-source models (LLaMA, Mistral, Falcon). tiktoken is OpenAI-specific. If you are working with non-OpenAI models, use the tokenizer that ships with that model. Each model has its own vocabulary and token counts will differ.
Tiktoken in Python: Install, Encode, Count
Here is everything you need to know to start using tiktoken in under 5 minutes.
Install tiktoken
pip install tiktokenBasic Usage: Encode and Count Tokens
import tiktoken
# Load the encoding for GPT-4o (uses o200k_base)
enc = tiktoken.encoding_for_model('gpt-4o')
text = 'What are tokens in AI?'
tokens = enc.encode(text)
print('Token IDs:', tokens)
# Output: Token IDs: [3923, 527, 11460, 304, 15592, 30]
print('Token count:', len(tokens))
# Output: Token count: 6See How Words Get Split
# See the actual text of each token
enc = tiktoken.get_encoding('cl100k_base'
for token_id in enc.encode('tokenization is fascinating'):
print(f'{token_id:6} -> {repr(enc.decode([token_id]))}')
# Output (example):
# 5963 -> 'token'
# 2065 -> 'ization'
# 374 -> ' is'
# 27387 -> ' fascinating'Count Tokens for a Chat Conversation
def count_tokens(messages: list, model: str = 'gpt-4o') -> int:
enc = tiktoken.encoding_for_model(model)
total = 0
for message in messages:
# 4 tokens per message overhead
total += 4
for key, value in message.items():
total += len(enc.encode(value))
total += 2 # reply priming
return total
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain tokens in AI."}
]
print(f'Total tokens: {count_tokens(messages)}')
# Total tokens: ~20-25Note for npm/JavaScript users: the community-supported @dqbd/tiktoken package brings tiktoken to Node.js via WASM bindings. OpenAI officially recommends it. Install with: npm install @dqbd/tiktoken
cl100k_base vs o200k_base: Which Encoding Does Your Model Use?
Tiktoken supports multiple encoding schemes, each matching a different generation of OpenAI models. Using the wrong encoding for your model gives you wrong token counts, which leads to cost estimation errors and unexpected context-limit hits.
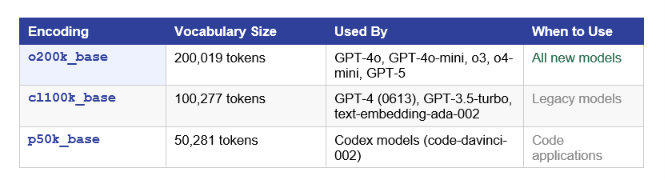
The jump from 100K to 200K vocabulary in o200k_base means the model can represent more words as single tokens. This reduces token counts, especially for multilingual content and code. If you are building production systems today, use o200k_base as your default.
In August 2025, OpenAI also released o200k_harmony as part of its latest tokenizer update, adding structured token types for role-based prompting, tool calls, and message channels. It is the most advanced OpenAI tokenizer available and comes bundled with the latest GPT-5-class models.
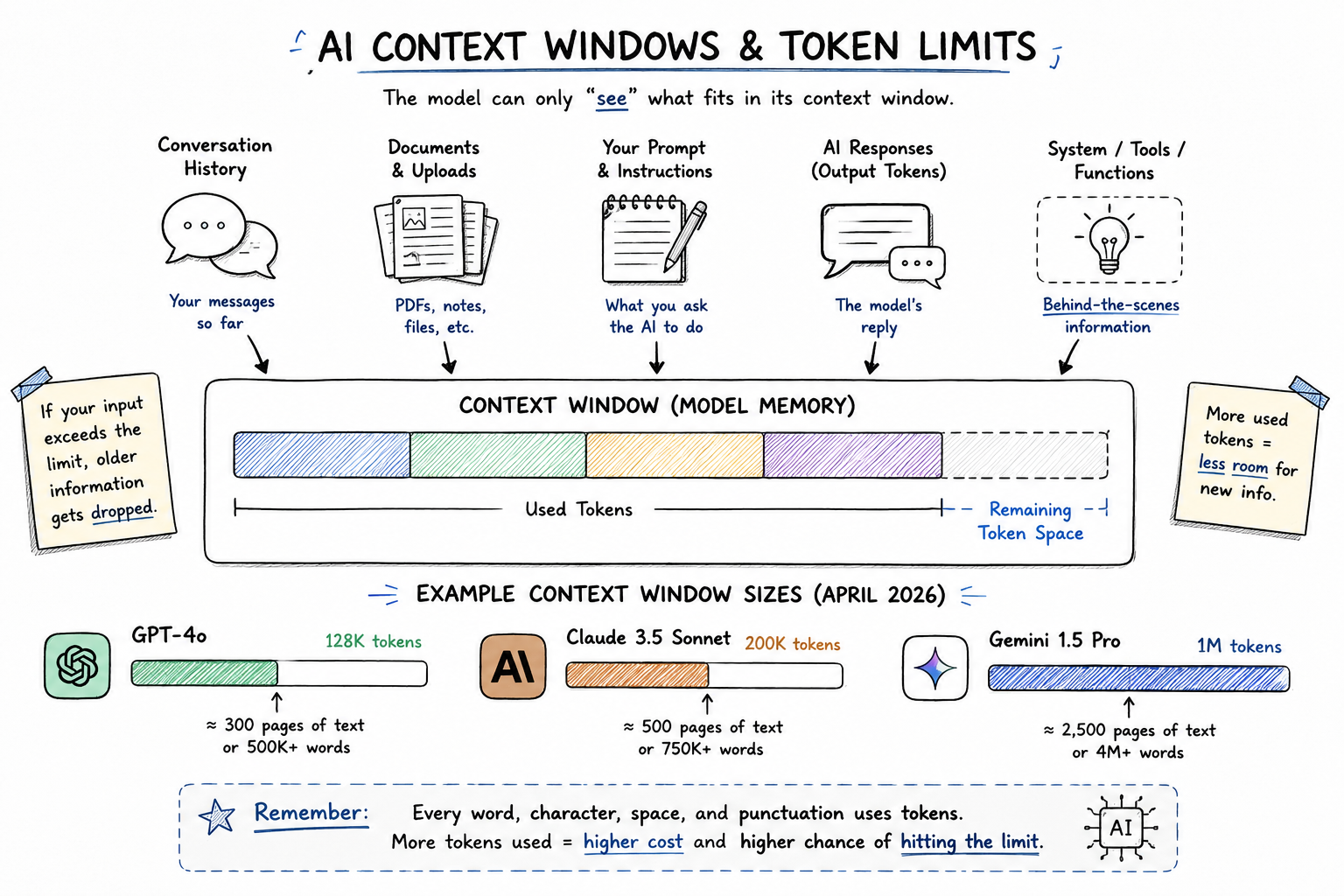
Token Limits and Context Windows: Why They Matter
Every LLM has a context window. This is the maximum number of tokens the model can hold in its active memory at once. Think of it as the model's working RAM. When you exceed the context window, the model starts forgetting earlier parts of the conversation.

The context window is both a ceiling and a cost driver. Everything in the context window, including system prompts, conversation history, and documents you paste in, costs input tokens every single time you send a message. A long conversation or a large document pasted into context can add thousands of tokens to every request.
The practical mistake I see constantly: people paste a 50-page PDF into a chat window and wonder why their API bill is high. That PDF is re-tokenized on every message. Structure your context carefully.
How Many Words Are 1,000 Tokens? (Practical Token Math)
This is the most Googled token question, so here is a clear answer with real numbers.
For standard English prose: 1,000 tokens is approximately 750 words. For comparison, the average blog post you're reading right now is around 2,000-3,000 tokens.
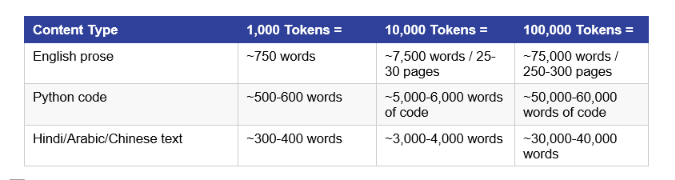
Non-English Languages Use More Tokens
This is a real cost and fairness issue. Hindi, Arabic, Chinese, and Japanese text uses 2-3x more tokens than equivalent English text with GPT-4 models. A 500-word Hindi paragraph might cost you 1,400+ tokens vs. 660 tokens for the same content in English. OpenAI has been improving multilingual efficiency with newer encodings, and o200k_base is meaningfully better than cl100k_base for non-English content.
How Tokens Affect Cost and What You Can Do About It
Yes, AI tokens cost money when you use the API directly. Claude.ai, ChatGPT Plus, and Gemini Advanced use subscription models, so individual users don't see per-token billing. But every company or developer building AI products pays per token.
Here is the economic reality for 2026 AI applications:
GPT-4o: $2.50 / 1M input tokens, $10.00 / 1M output tokens (OpenAI, May 2026)
GPT-4o-mini: $0.15 / 1M input tokens, $0.60 / 1M output tokens. 16x cheaper for most tasks Claude Sonnet 4.6: $3.00 / 1M input, $15.00 / 1M output (Anthropic, May 2026)
Gemini 2.0 Flash: $0.075 / 1M input, $0.30 / 1M output. Cheapest major model for high-volume use
5 practical ways to reduce your token spend:
Use tiktoken before sending any prompt to estimate and cap token counts.
Prefer cheaper models (gpt-4o-mini, Gemini Flash) for tasks that don't need maximum quality.
Compress system prompts. A 2,000-token system message costs you money on every single call.
Use caching where available. Anthropic and OpenAI both offer prompt caching that reduces cost on repeated context.
Summarize long conversation history instead of passing the entire transcript each time.
FAQ: Your Token Questions Answered
Q: What is a token in AI?
A token is the smallest unit of text that an AI language model processes. It can be a word, part of a word, punctuation, or a space. The sentence 'What is AI?' contains 5 tokens using GPT-4's encoding: ['What', ' is', ' AI', '?', and the initial token]. LLMs like GPT-4 and Claude read tokens, not raw text.
Q: How many words is 1,000 tokens?
In English, 1,000 tokens is approximately 750 words. The general rule is 1 token equals roughly 0.75 English words, or about 4 characters. For non-English languages like Hindi, Chinese, or Arabic, 1,000 tokens may only be 300-500 words, since those scripts require more tokens per character.
Q: What is tiktoken and what is it used for?
Tiktoken is OpenAI's official open-source Python library for tokenizing text using the exact same byte-pair encoding that GPT models use. Developers use it to count tokens before sending API calls, estimate costs, ensure prompts fit within context windows, and debug tokenization issues. It is available at github.com/openai/tiktoken and installable via pip install tiktoken.
Q: What is cl100k_base in tiktoken?
cl100k_base is the encoding scheme (tokenizer vocabulary) used by GPT-4, GPT-3.5-turbo, and text-embedding-ada-002 models. It has a vocabulary of 100,277 unique tokens. The newer o200k_base encoding, used by GPT-4o and later models, has 200,019 tokens and is more efficient, especially for multilingual content and code.
Q: What is the token limit in ChatGPT?
GPT-4o has a context window of 128,000 tokens (roughly 96,000 words or 300 pages of text). ChatGPT's free tier (using GPT-4o-mini) has a smaller effective context. The context window includes everything: your system prompt, conversation history, and the current message. Exceeding it causes older messages to be dropped.
Q: Do AI tokens cost money?
Yes, for API usage. OpenAI charges $2.50 per million input tokens and $10.00 per million output tokens for GPT-4o (May 2026). GPT-4o-mini is 16x cheaper at $0.15 / $0.60 per million. Subscription products like ChatGPT Plus ($20/month) include tokens in the subscription, so individual users don't see per-token bills.
Q: How are tokens counted for pricing?
Both input and output tokens count toward billing. Input tokens include your system prompt, the full conversation history, and your current message. Output tokens are every token the model generates in its response. Use tiktoken locally to count tokens before sending any request to get exact cost estimates.
Q: How does GPT generate text token by token?
GPT models generate text through a process called autoregressive generation. Given a sequence of input tokens, the model calculates a probability distribution over all possible next tokens (the full 100K-200K vocabulary). It selects one token based on that distribution, appends it to the sequence, and repeats. This continues until it generates a stop token or reaches the max output limit.
Recommended Blogs
If this blog made tokens click for you, these will level you up further:
What Is a Large Language Model? The full story behind GPT, Claude, and Gemini.
Prompt Engineering 2026: Now that you understand tokens, learn to write prompts that use them efficiently.
What Is Agentic AI? The next evolution beyond chatbots. Agents use token budgets actively and autonomously.
Learn AI From Scratch in 2026: The full learning roadmap. Tokens are just the start.
AI moves fast. 5 minutes a day keeps you ahead without burning out.
References
tiktoken on PyPI: / (Released Oct 6, 2025 - v0.9.0)
DataCamp - Tiktoken Tutorial: OpenAI's Python Library for Tokenizing Text:
Sennrich et al. (2016) - Neural Machine Translation of Rare Words with Subword Units (BPE paper):
Unrot.co Learn AI in 5 Minutes a Day

