


What Is Fine-Tuning an AI Model? (And Do You Actually Need It?)
Here is the thing about fine-tuning that nobody says clearly enough: most people who want it don't need it.
Fine-tuning appears in job descriptions, pitch decks, product announcements, and AI news headlines constantly. It sounds like the serious, grown-up way to use AI — the thing you do when you've moved beyond 'just prompting.' That framing is wrong. It is also expensive if you act on it when simpler tools would have done the job.
I am going to explain what fine-tuning actually is — no math, no neural network diagrams — and then give you an honest answer to the question most guides skip: whether you actually need it.
The short answer: fine-tuning is the right choice in four specific situations. For everything else, prompt engineering or RAG will get you there faster and cheaper.
The Simplest Way to Understand Fine-Tuning
Here is the analogy that makes fine-tuning click every time.
Imagine you hired an extraordinary generalist — someone who spent 20 years reading everything: law, medicine, science, literature, code, history, marketing. They can hold a conversation about anything. They write well, reason carefully, and rarely get confused.
Now you need this person to work full-time in your customer support team for your medical device company. They will need to learn your specific products, your regulatory requirements, your exact communication style, how you handle complaints, and the precise language your compliance team requires.
You could give them a detailed briefing document and trust them to refer to it before each call. That is prompt engineering — fast, flexible, no commitment.
Or you could send them on a structured three-month training programme at your company, where they work through hundreds of past cases until that knowledge is part of how they think, not something they look up.
That is fine-tuning. The training changes how they respond, not just what they know.
In technical terms: a base language model (GPT-4o, Llama 4, Mistral) is pre-trained on enormous amounts of general text data. Fine-tuning continues that training on a smaller, task-specific dataset — adjusting the model's internal mathematical parameters (its weights) so it produces outputs tailored to your specific domain, style, or task.
The critical insight: the training programme changes the employee's default behaviour. Prompt engineering changes their instructions for a specific task. Both are useful. They solve different problems.
What Fine-Tuning Actually Changes (And What It Doesn't)
This is where most explanations fall short. Fine-tuning is not magic. It changes some things reliably. It does not change others at all.
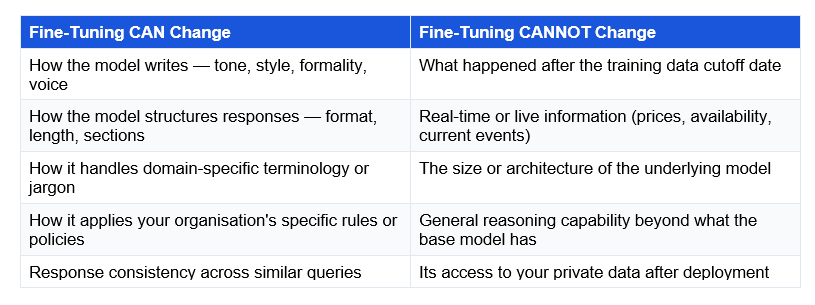
The most common misunderstanding: fine-tuning is not an efficient way to teach a model new facts. The model may appear to memorise training examples but will not reliably generalise to new facts phrased differently. If you need the model to know your current product catalogue, pricing, or documentation — and if those things change — RAG is the right tool. Fine-tuning is for changing how the model behaves, not what it knows
The rule that saves most teams from expensive mistakes: Use RAG for knowledge. Use fine-tuning for behaviour. Use prompt engineering for both — unless you have a specific reason not to.
Fine-Tuning vs Prompt Engineering vs RAG — The Honest Comparison
These three techniques are constantly compared as though you must pick one. The reality in 2026 is that the best production AI systems use all three together: RAG for factual grounding, fine-tuning for behavioural specialisation, prompt engineering for per-request control. But they serve different primary purposes, and the decision of which to reach for first matters enormously for your time and budget
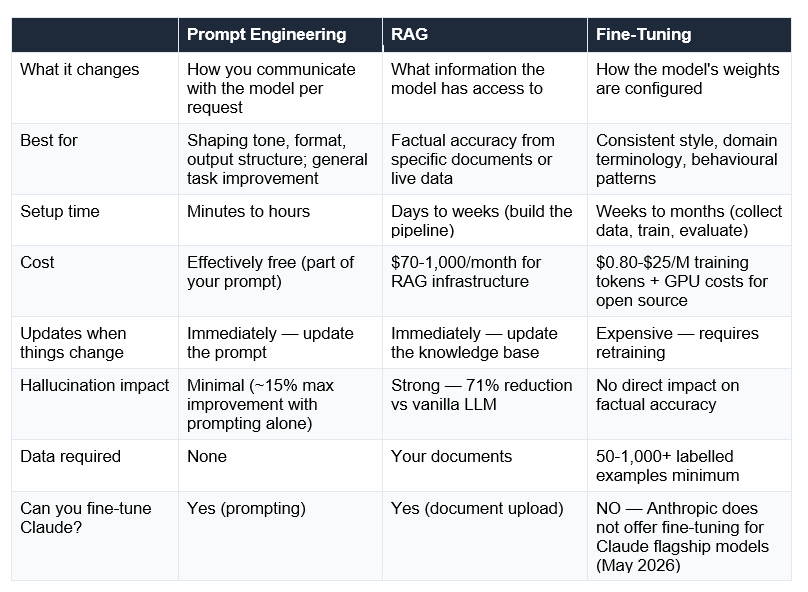
The ordering that experts consistently recommend: Prompt engineering first (hours, free). If you need knowledge from specific documents → add RAG. If you need consistent behavioural changes across thousands of requests and have labelled training data → then consider fine-tuning.
When You Actually Need Fine-Tuning (4 Real Situations)
After all the hype, here are the four specific situations where fine-tuning genuinely pays off — and the honest explanation of why it pays off in each case:
Situation 1: Consistent tone and style at scale
If you need every output from an AI system to sound like it was written by a specific person or brand — consistent vocabulary, sentence structure, formality level, personality — fine-tuning is the most reliable way to achieve this. Prompt engineering can approximate it, but tone consistency degrades across long conversations and complex tasks. A fine-tuned model that has absorbed 500+ examples of your brand voice produces that voice by default, without needing instruction.
Real example: Bloomberg built a fine-tuned version of BERT (a language model) called BloombergGPT, trained on 363 billion tokens of financial data. It consistently uses financial terminology, handles Bloomberg-specific data formats, and maintains the precise tone required for financial journalism — capabilities that prompt engineering alone could not reliably deliver at the scale Bloomberg operates at.
Situation 2: Domain-specific terminology and reasoning
In highly technical fields — medicine, law, cybersecurity, specific engineering domains — base models know general terminology but can make subtle errors on specialised language. A medical device company fine-tuning GPT-4o on thousands of patient report examples produces a model that handles clinical terminology, report structures, and regulatory language with dramatically improved precision on that specific task.
The distinction from RAG: RAG gives the model the relevant documents at query time. Fine-tuning changes how the model processes and writes about the domain even without documents being provided. For very high-volume tasks where retrieval latency matters, this distinction is significant.
Situation 3: Cost reduction at high volume
This is an underappreciated reason to fine-tune, and it is increasingly how 2026 AI teams justify the investment. If you can fine-tune a smaller, cheaper model (GPT-4o-mini, Llama 4 Scout, Phi-4) to match the quality of a larger model (GPT-5.5, Claude Opus 4.7) on your specific task, you dramatically reduce per-request inference costs.
The 2026 pattern emerging in enterprise AI: use GPT-5.5 (the 'teacher') to generate high-quality synthetic training data, then fine-tune GPT-4o-mini or Llama 4-8B (the 'student'). The result is near-flagship quality on your specific task at a fraction of the inference cost. At 10,000 requests per day, this cost difference compounds into significant savings.
Concrete example: Training a GPT-4o-mini fine-tune on 100K tokens costs approximately $90 at OpenAI's current rates. If the fine-tuned model eliminates a 400-token system prompt from each request, the training cost pays for itself in under a day at 10,000 requests per day.
Situation 4: Privacy and data sensitivity
When your task requires working with proprietary or sensitive information, fine-tuning can be preferable to RAG because it bakes knowledge into the model weights rather than retrieving documents at inference time. For organisations with strict data governance, legal constraints, or regulatory obligations (HIPAA, GDPR, financial services regulation), a fine-tuned model that doesn't need to query external systems at runtime can satisfy compliance requirements that RAG architectures cannot.
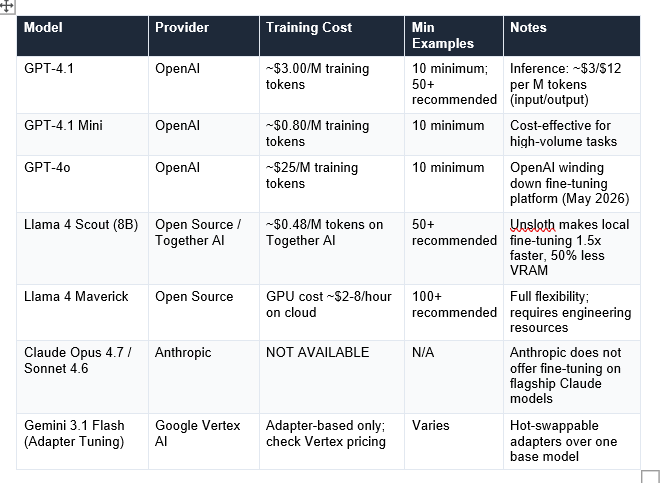
What Fine-Tuning Costs in 2026
The cost of fine-tuning has dropped significantly over the past two years. Here is an honest breakdown:
The hidden costs most articles do not mention:
Data preparation: This is almost always the biggest cost. Collecting, cleaning, and formatting 500-1,000 high-quality labelled examples can take weeks. Poor training data produces a worse model than good prompting.
Evaluation: You need a held-out test set and a systematic evaluation process. Without this, you do not know if your fine-tuned model is actually better than the base model on your task.
Maintenance: When the base model gets updated, you may need to retrain. When your requirements change, you need new data and a new training run. Each cycle costs $500-$5,000+ and takes days. Compare this to RAG, where updating knowledge means updating documents.
Inference premium: OpenAI charges more for fine-tuned model inference than for the base model. Google charges the same rate for Gemini adapter tuning. Factor this into long-term cost projections.
Budget rule of thumb: If your fine-tuning project total cost (data preparation, training, evaluation, inference premium, maintenance over 6 months) is not clearly cheaper or better than prompt engineering + RAG for the same outcome, the math does not work in fine-tuning's favour. Most projects where teams reach for fine-tuning first end up discovering this after the fact.
Real Examples of Fine-Tuned Models in 2026
These are the categories where fine-tuning is genuinely deployed in production in 2026:

LoRA and QLoRA — Why They Matter Even If You're Not an Engineer
Full fine-tuning — adjusting every single parameter in a large model — is prohibitively expensive for most organisations. LoRA (Low-Rank Adaptation) changed that.
LoRA works by adding small trainable matrices to specific layers of the model, rather than retraining all parameters. The original LoRA paper by Hu et al. (2021) demonstrated that for GPT-3's 175 billion parameters, LoRA reduced trainable parameters to just 18 million — a 10,000x reduction — while matching or exceeding full fine-tuning quality. Research published in March 2026 confirmed that standard LoRA reduces catastrophic forgetting from 19.9% average in full fine-tuning to just 0.6% in sequential fine-tuning tasks (p=0.002).
QLoRA combines LoRA with quantisation (compressing the model to 4-bit precision), making it possible to fine-tune a 65-billion parameter model on a single 48GB consumer GPU. This opened fine-tuning to individual developers and small teams without access to expensive GPU clusters.
Why this matters for non-engineers: LoRA and QLoRA are the techniques that make tools like Unsloth and Hugging Face's PEFT library work. In 2026, Unsloth makes Llama 4 fine-tuning 1.5x faster and uses 50% less VRAM than previous approaches, enabling fine-tuning on consumer hardware. These tools mean fine-tuning is no longer reserved for companies with large ML infrastructure budgets.
The Decision Framework: Should YOU Fine-Tune?
Walk through this in order. Stop when you hit a 'YES':
Question 1: Does the model need access to specific documents, databases, or real-time information to answer correctly?
YES → Use RAG — fine-tuning cannot provide dynamic knowledge. RAG gives the model the relevant content at query time.
NO → Move to Question 2.
Question 2: Can a well-crafted prompt (with examples) get you 80%+ of the way to the output quality you need?
YES → Use prompt engineering — it is free, instant, and flexible. Fine-tuning for what prompting can solve is almost always a mistake.
NO → Move to Question 3.
Question 3: Do you need the model to consistently behave in a specific way — tone, format, domain terminology, brand voice — across thousands of requests without detailed prompting?
YES → Fine-tuning is worth evaluating. Move to Question 4.
NO → You likely do not need fine-tuning. Re-examine Questions 1 and 2.
Question 4: Do you have at least 50-100 high-quality labelled examples of the output you want, and the budget/time for a training run + evaluation cycle?
YES → Proceed with fine-tuning. Start with a smaller model (GPT-4.1 Mini, Llama 4 Scout) to validate the approach before committing to larger training costs.
NO → Collect the data first. Fine-tuning without quality training data produces worse results than good prompting.
The honest conclusion from this framework: the vast majority of use cases I encounter are answered by Questions 1 or 2. Fine-tuning makes sense for a smaller set of use cases than the hype suggests — but for those specific use cases, it is genuinely the right tool.
Frequently Asked Questions
Q: What is fine-tuning an AI model in simple terms?
Fine-tuning is the process of taking a pre-trained AI model — like GPT-4o or Llama 4 — and training it further on a smaller, task-specific dataset. This adjusts the model's internal parameters so it produces outputs tailored to your specific domain, writing style, or task. Unlike prompt engineering (which changes your instructions per request) or RAG (which gives the model relevant documents), fine-tuning changes how the model responds by default — even without additional instructions.
Q: What is the difference between fine-tuning and prompt engineering?
Prompt engineering changes what you tell the model to do in a specific interaction. Fine-tuning changes how the model is configured at a fundamental level. Prompt engineering is free, flexible, and reversible — you can change prompts instantly. Fine-tuning requires training data, costs money, takes days to weeks, and cannot be updated instantly when requirements change. For the vast majority of tasks, prompt engineering should be tried first. Fine-tuning is warranted when you need consistent behaviour at scale that prompting cannot reliably deliver.
Q: When should I use fine-tuning vs RAG?
Use RAG when you need the model to answer accurately from specific documents, databases, or real-time information — especially when that information changes frequently. Use fine-tuning when you need the model to behave differently by default — in tone, style, domain terminology, or structured output format — regardless of the document it is reading. The clearest rule: use RAG for knowledge, use fine-tuning for behaviour. Many production systems use both.
Q: Can you fine-tune Claude or Gemini?
As of May 2026, Anthropic does not offer fine-tuning for Claude flagship models (Opus 4.7, Sonnet 4.6). You can customise Claude's behaviour through prompt engineering, Projects, and system prompts. Google offers Adapter Tuning for Gemini 3 Flash on Vertex AI — a form of parameter-efficient fine-tuning with hot-swappable adapters. OpenAI offers fine-tuning for GPT-4.1 and GPT-4.1 Mini, though it announced in May 2026 that it is winding down its fine-tuning platform for new users.
Q: What is catastrophic forgetting in AI fine-tuning?
Catastrophic forgetting is when fine-tuning a model on a narrow task causes it to lose general capabilities it had before. A model fine-tuned on medical reports might become worse at general writing or coding tasks. Full fine-tuning shows approximately 19.9% average forgetting across tasks according to March 2026 research. LoRA (Low-Rank Adaptation) dramatically reduces this — to approximately 0.6% in the same conditions. In 2026, the practical solution for preventing catastrophic forgetting is either using LoRA-based fine-tuning or mixing approximately 10% of general training data ('replay buffers') into your fine-tuning dataset.
Q: How much does fine-tuning an AI model cost in 2026?
Training costs vary significantly: GPT-4.1 costs approximately $3/M training tokens on OpenAI; GPT-4.1 Mini costs approximately $0.80/M tokens; open-source models via Together AI cost approximately $0.48/M tokens for smaller models. A practical fine-tuning run on GPT-4.1 Mini with 100,000 tokens costs roughly $80-100. But the real cost is usually data preparation — collecting, cleaning, and formatting 500-1,000 high-quality examples often takes weeks of human time. Plus ongoing maintenance: every time requirements change or the base model updates, you may need a new training cycle at $500-$5,000+.
Q: What is LoRA and why does it matter for fine-tuning?
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning technique that adds small trainable matrices to specific model layers rather than retraining all parameters. The original LoRA paper showed it reduced trainable parameters by 10,000x versus full fine-tuning while matching output quality. QLoRA extends this by compressing the model to 4-bit precision, enabling fine-tuning of 65-billion parameter models on a single consumer GPU. In 2026, LoRA-based tools like Unsloth make Llama 4 fine-tuning 1.5x faster with 50% less VRAM, putting fine-tuning within reach of individual developers and small teams.
Q: How many examples do I need to fine-tune a model?
OpenAI accepts as few as 10 examples to start a fine-tuning job, but results with minimal data are typically worse than good prompt engineering. Most practitioners recommend 50-100 examples as a baseline to see genuine improvement. For complex tasks, 500-1,000 high-quality labelled examples tend to produce reliable results. The emphasis is on quality over quantity — 100 well-crafted examples consistently outperform 1,000 inconsistent ones. Data preparation is almost always the most time-consuming and expensive part of a fine-tuning project.
Fine-tuning is Advanced. But understanding it doesn't have to be.
Unrot's Advanced Path covers Fine-Tuning LLMs, LoRA, and QLoRA — each concept explained in 5 minutes, built for learners not engineers. Free in the app.
app.unrot.co → Advanced Path → Fine-Tuning LLMs
References
Published on Unrot.co | May 2026

