

What Is a Vector Database? The AI Memory System Explained for Beginners
Something happened when I searched Spotify last week.
I typed: "late night driving city lights." Not an artist. Not a song title. Just a vibe. Spotify returned a playlist of synthwave, lo-fi jazz, and ambient electronic music that was — somehow — exactly right. No track on that playlist mentioned 'late night' or 'city lights' in its title or description.
That experience has a technical name: semantic search. And the infrastructure that makes it possible is a vector database. The same technology that powered that Spotify search also powers NotebookLM's ability to find the relevant paragraph in your 200-page PDF, Perplexity's ability to retrieve the right source for your question, and every RAG system inside every major AI chatbot in 2026.
Vector database adoption grew 377% year over year — the fastest growth of any LLM-related technology, according to IBM's research. They went from a niche ML infrastructure term to something that appears in AI job descriptions, product announcements, and news articles daily. This post explains what they are, how they work, and why they have become the backbone of the AI era.
The Problem Vector Databases Solve
To understand why vector databases exist, you need to understand what regular databases cannot do.
Traditional databases — MySQL, PostgreSQL, SQLite — are exceptional at exact-match queries. They were designed for structured data: names, numbers, dates, categories. Ask them 'find all users where city = London and age > 30' and they answer instantly. They are reliable, fast, and well-understood. For decades, they handled most of the world's data needs perfectly.
The problem arrives with unstructured data and meaning-based queries. What happens when you need to find:
Songs that sound similar to this one (not the same genre — similar
Documents that discuss the same concept, even if they use different words
Images that look visually similar to this image
Customer support questions that mean the same thing but are phrased differently
Products that are relevant to what someone is looking for, not just what they typed
A regular database cannot answer any of these questions. It can match exact values. It cannot match meaning. If you search a SQL database for 'plumbing repair' and the relevant document says 'dripping tap solution,' you get zero results. The keyword does not match.
This is the problem vector databases solve. They store data as numerical representations of meaning, not as raw text or numbers. And they search by proximity of meaning, not exact keyword match.
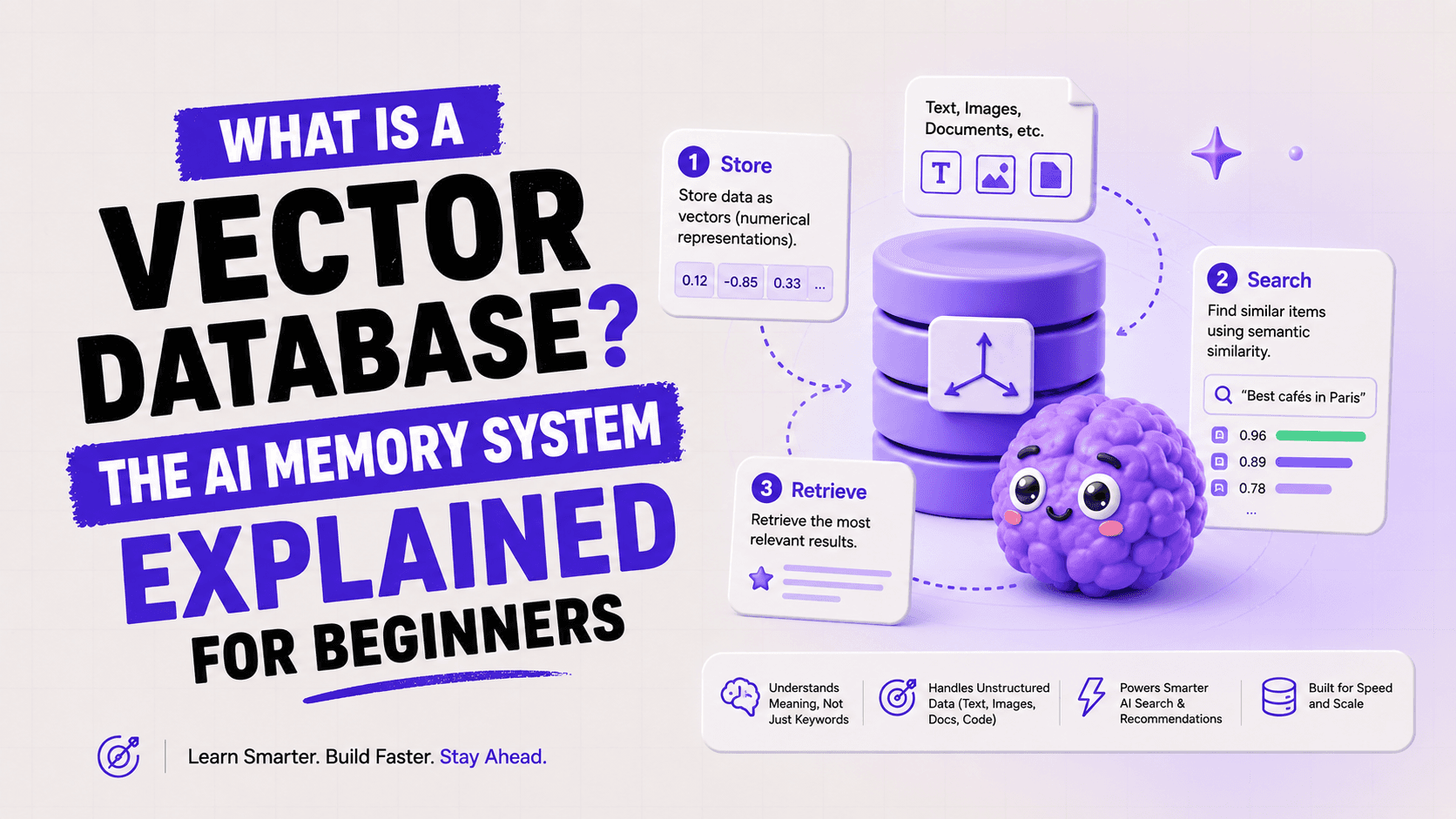
One-sentence definition: A vector database is a database that stores data as numerical representations of meaning (called embeddings or vectors), and retrieves results by semantic similarity — finding what means the same thing — rather than by exact keyword matching.
What a Vector Actually Is (The Map Analogy)
This is the part where most explanations lose beginners. They introduce terms like 'high-dimensional vector space' and suddenly everything feels inaccessible. Let me try a different path.
The city map analogy:
Imagine a map of a city. Every location on the map has coordinates: latitude and longitude. Two numbers that uniquely identify exactly where something is.
Things that are physically close on the map — a coffee shop and a bookstore on the same street — have coordinates that are numerically similar. Things that are far apart — a suburb and the city centre — have very different coordinates.
Now imagine that instead of a 2D map of a city, you have a 1,536-dimensional map of meaning. Every word, sentence, document, image, or song gets assigned a position in that enormous space based on its meaning. Things that mean similar things — 'car' and 'automobile', 'plumbing repair' and 'dripping tap solution' — end up positioned close to each other. Things with different meanings end up far apart.
A vector is just those coordinates. A list of numbers that represents where something sits in the meaning-space.
A vector database is the system that stores all of those coordinates and can quickly find which ones are closest to a query.
In technical terms: an embedding model (like OpenAI's text-embedding-3-small) converts any text into a list of 1,536 numbers. Those numbers are the vector. The embedding model is trained to position semantically similar content near each other in that 1,536-dimensional space. A vector database stores those lists and runs fast similarity searches across them.
The specific similarity measure most commonly used is cosine similarity — it measures the angle between two vectors in that high-dimensional space rather than their absolute distance. Two vectors pointing in nearly the same direction (small angle) are semantically similar. Vectors pointing in very different directions are semantically dissimilar.
How a Vector Database Works — Step by Step
Here is the process from raw content to search result:

Speed note: A well-built vector database can search across 100 million vectors in 30-100 milliseconds. This is what makes real-time semantic search in production applications possible — Qdrant achieves 30-40ms p99 latency at 100M vectors according to April 2026 benchmarks.
Vector Databases vs Regular SQL Databases
The most important thing to understand: vector databases do not replace SQL databases. They solve a fundamentally different problem. By 2026, the industry has moved past the 'vector vs SQL' debate — production systems use both, side by side, for different jobs.
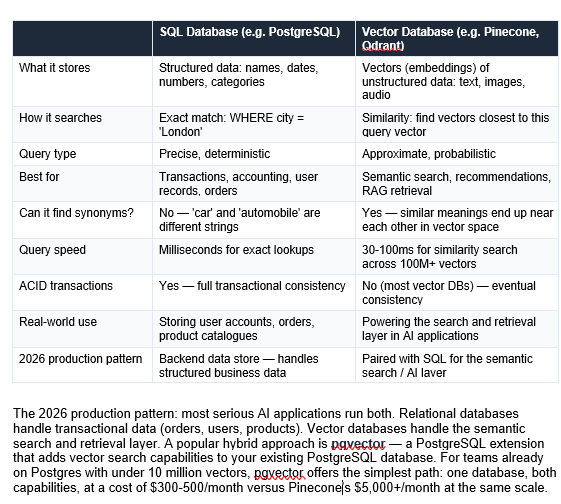
The 2026 production pattern: most serious AI applications run both. Relational databases handle transactional data (orders, users, products). Vector databases handle the semantic search and retrieval layer. A popular hybrid approach is pgvector — a PostgreSQL extension that adds vector search capabilities to your existing PostgreSQL database. For teams already on Postgres with under 10 million vectors, pgvector offers the simplest path: one database, both capabilities, at a cost of $300-500/month versus Pinecone's $5,000+/month at the same scale.
The Major Vector Databases in 2026
The vector database market has consolidated around a clear set of options, each with a distinct use case sweet spot. Here is an honest comparison for non-engineers:
Pinecone — The fully-managed, zero-ops leader
Open Source: No (proprietary managed service)
Best For: Teams that want to ship fast without managing infrastructure; enterprise at scale
Free Tier: Free tier available; paid from ~$70/month; ~$5,000+/month at 100M vectors
Scale Ceiling: Billions of vectors; handles the largest production workloads
Chroma — The developer-friendly prototyping champion
Open Source: Yes — Apache 2.0 licence; self-hostable
Best For: Developers building prototypes, learning RAG, early-stage AI apps
Free Tier: Completely free; runs locally; no signup required
Scale Ceiling: ~100M vectors; not designed for Pinecone or Milvus scale
Qdrant — The performance leader for filtered search
Open Source: Yes — Apache 2.0; also has Qdrant Cloud (managed)
Best For: Teams needing fast filtered search: 'find documents similar to X that are also tagged Y'
Free Tier: Open-source self-hosted free; Qdrant Cloud from ~$25/month
Scale Ceiling: Billions of vectors; 30-40ms p99 latency at 100M vectors (fastest in class)
Weaviate — The hybrid search champion
Open Source: Yes — BSD-3; Weaviate Cloud also available
Best For: Teams needing vector search + keyword search combined; complex AI applications
Free Tier: Open-source self-hosted free; Weaviate Cloud from ~$25/month
Scale Ceiling: Billions of vectors; excellent for combining vector and BM25 keyword search
Milvus — The billion-scale open-source engine
Open Source: Yes — Apache 2.0; managed via Zilliz Cloud
Best For: Teams with very large-scale requirements who want open-source
Free Tier: Open-source self-hosted free; Zilliz Cloud from ~$65/month
Scale Ceiling: Designed for billions of vectors with distributed architecture
pgvector — The Postgres-native option
Open Source: Yes — PostgreSQL extension, completely free
Best For: Teams already on PostgreSQL who need vector search without adding another service
Free Tier: Free — it's a PostgreSQL extension
Scale Ceiling: 100M+ vectors on PostgreSQL; not ideal for dedicated vector-heavy workloads
Quick decision: Starting out or prototyping? Use Chroma — free, local, no configuration. Building a production app on PostgreSQL? Add pgvector — one service, SQL + vectors. Need managed simplicity at scale? Pinecone. Need filtered search performance? Qdrant. Need hybrid vector + keyword search? Weaviate. Need open-source at billion scale? Milvus.
Real Products Powered by Vector Databases
Vector databases are not abstract infrastructure — they run inside products you use every day. Here is what they are powering right now:

Why Vector Databases Matter for AI — The RAG Connection
If you have read the Unrot post on RAG (Retrieval-Augmented Generation), you already know the core insight: RAG connects an AI model to a real knowledge source at query time instead of letting it guess from training data alone. The vector database is the library that makes RAG's retrieval step possible.
Here is how they connect:
Documents (knowledge base, product catalogue, company policies, research papers) are converted into embeddings and stored in the vector database.
A user asks a question — 'What is the refund policy for orders over 30 days?'
The question is converted to a vector by the same embedding model.
The vector database finds the stored vectors most similar to the question — retrieving the specific policy clauses most relevant to this query.
Those retrieved passages are injected into the language model's context window along with the original question.
The language model generates an answer grounded in the retrieved text — accurate, specific, citable, not hallucinated.
The vector database is what makes step 4 possible at speed and scale. Without it, a RAG system would need to compare the query against every stored document one by one — infeasible at any meaningful scale. The ANN index in a vector database makes this comparison across millions of documents happen in milliseconds.
The single stat that explains why this matters: RAG reduces AI hallucination rates by approximately 71% compared to standard LLMs. The vector database is the retrieval engine that makes RAG work. Without it, there is no RAG. Without RAG, hallucination rates stay at 15-52% depending on the domain. The vector database is therefore one of the most practically important pieces of AI infrastructure in 2026.
Why You'll Keep Hearing This Term
Vector database adoption grew 377% year over year, according to IBM's 2025 research — the fastest growth of any LLM-related technology. The market is projected to grow from $1.2 billion in 2024 to $9.86 billion by 2030 at a 49% annual growth rate, according to MarketsandMarkets.
The reason is straightforward: every AI product that needs to work with specific knowledge — your documents, your data, your company's information — needs a retrieval layer. And the retrieval layer that works with meaning (not just keywords) is built on vector databases. As AI moves from generic chatbots to specialised knowledge products, the vector database becomes essential infrastructure rather than an optional optimisation.
Specifically: as AI agents become the dominant AI pattern in 2026, vector databases become their long-term memory — the place agents store and retrieve knowledge across sessions and tasks. Eight specific vector databases now anchor production AI-agent workloads: Pinecone, Qdrant, Weaviate, Milvus, Chroma, pgvector, Vertex Vector (GCP), and Vespa.
For anyone building with AI, working in AI product roles, or trying to understand how AI products work under the hood: vector databases are not optional vocabulary. They are foundational.
Frequently Asked Questions
Q: What is a vector database in simple terms?
A vector database is a database that stores data as lists of numbers (called vectors or embeddings) that represent meaning. Instead of searching by exact keyword match, it searches by semantic similarity — finding content that means the same thing even if it uses different words. Spotify uses one to recommend songs matching your vibe. NotebookLM uses one to find relevant passages in your documents. RAG systems use them to retrieve accurate context for AI responses.
Q: What is the difference between a vector database and a regular SQL database?
SQL databases store structured data (names, numbers, dates) and search by exact match — they find rows that precisely match your query conditions. Vector databases store embeddings (numerical representations of meaning) and search by similarity — they find content that is semantically similar to your query even if no exact keywords match. In 2026, production AI systems use both: SQL for structured business data and transactions; vector databases for the semantic search and RAG retrieval layer.
Q: What is the best vector database for beginners in 2026?
Chroma is the most beginner-friendly vector database in 2026. It is free, open-source, runs entirely locally without a server, and integrates directly with LangChain and LlamaIndex. You can have a working semantic search system on your laptop in under 30 minutes. For teams already using PostgreSQL who want to add vector search to an existing database, pgvector is the simplest path with the least additional infrastructure.
Q: What is the relationship between RAG and vector databases?
A vector database is the retrieval engine that makes RAG work. In a RAG system: your documents are converted to vectors (embeddings) and stored in the vector database. When a user asks a question, the question is also converted to a vector. The vector database finds the stored vectors most similar to the question — retrieving the relevant documents. Those documents are injected into the AI model's context window so it can answer from real information instead of training data. Without the vector database, the retrieval step in RAG cannot happen efficiently at scale.
Q: What is semantic search and how is it different from keyword search?
Keyword search finds documents containing the exact words you typed. Semantic search finds documents that mean the same thing you meant — even if they use completely different words. A keyword search for 'running shoes for wide feet' would miss a product description that says 'broad-fit athletic footwear.' A semantic search powered by a vector database would return it, because the meaning is similar. Vector databases enable semantic search by positioning similar meanings close together in vector space and retrieving results by proximity.
Q: Can vector databases replace SQL databases?
No, and they are not designed to. Vector databases solve a specific problem — semantic similarity search over high-dimensional embeddings — that traditional databases were not built for. They do not replace SQL for transactional queries, structured reporting, or ACID-compliant operations. In 2026, the standard production pattern is a polystore architecture: relational databases handle structured business data, vector databases handle the semantic search and AI retrieval layer. The two complement each other rather than competing.
Q: Is Pinecone free?
Pinecone offers a free tier with limited capacity — sufficient for prototyping and development. Production workloads at scale cost approximately $70/month at starter tier, rising to $5,000+/month at 100 million vectors. For teams on a tighter budget who need scale, Qdrant (open-source) and pgvector (free PostgreSQL extension) offer significantly lower costs. Chroma is completely free and runs locally — the best option for learning, prototyping, and small-scale production.
Q: What is a vector embedding and how does it relate to vector databases?
A vector embedding is the numerical representation that a vector database stores and searches. When text, images, or audio are passed through an embedding model (like OpenAI's text-embedding-3-small), the model converts them into a list of numbers — typically 1,536 to 3,072 numbers — that represents their meaning. These numbers are the embedding. The vector database stores those embeddings and runs similarity searches across them. The quality of the embedding model determines the quality of the semantic search; the vector database determines the speed and scale of retrieval.
Vector databases are the infrastructure of the AI era. Understand them in 5 minutes.
Unrot's Intermediate course on Vector Databases explains how similarity search works, what embeddings are, and how they connect to RAG — no engineering background required. Free in the app.
app.unrot.co → Intermediate Path → Vector Databases: Search by Meaning
References
Published on Unrot.co | May 2026

