


What Is RAG? How AI Stops Making Things Up
Here is a number that should stop you: RAG reduces AI hallucination rates by approximately 71% compared to standard language models, according to AllAboutAI's 2026 research.
If you have ever used NotebookLM, Perplexity, or uploaded a document into Claude and had it accurately answer questions about that specific document without making things up, you have used RAG. You just did not know it had a name.
RAG - Retrieval-Augmented Generation - is one of the most important AI techniques of 2026. Over 70% of new production AI systems use it as the default approach. Enterprise AI teams cite it as the most reliable fix for the hallucination problem. And yet most explanations of it start with words like 'embedding vector space' and lose everyone within two sentences.
This post explains RAG in plain English. What the problem is that it solves. How it works in three steps. Why it matters to you even if you will never build one. And how it compares to the two other techniques - prompt engineering and fine-tuning - that you may have heard alongside it.
The Problem RAG Solves — And Why It Matters
Every major AI model — ChatGPT, Claude, Gemini, Llama — is trained on a large dataset of text collected up to a certain date. After that training cutoff, the model's knowledge is frozen. It knows nothing about what happened afterward. It cannot access your company's internal documents. It cannot read the report you uploaded last week.
And yet when you ask it a question about those things, it does not say 'I don't know.' It generates an answer. The most statistically plausible-sounding answer, based on the patterns in its training data. Which is exactly how hallucinations happen: the model guesses, and the guess sounds authoritative.
There are three specific scenarios where this problem is most costly:
Outdated information: You ask about something that changed after the model's training cutoff. It gives you the old answer as though it is still current.
Private or proprietary data: You need answers based on your company's internal documents, your own research notes, or a report that was never published online. The model has never seen any of it.
Specific factual accuracy: You need a precise answer — a specific clause in a contract, a specific metric in a report. The model generates something that sounds right but is fabricated from patterns rather than retrieved from the actual document.
RAG solves all three of these problems by changing one fundamental thing: instead of letting the model guess from memory, RAG fetches the actual relevant information first, then lets the model answer from what it just retrieved.
One-sentence definition: RAG is an AI technique that connects a language model to an external knowledge source at the time of a query, so the model can answer using real, retrieved information instead of relying on its training data alone.
How RAG Works in 3 Steps (Plain English, No Jargon)
Most technical explanations of RAG start with 'vector embeddings' and 'semantic similarity scoring.' I am going to start with something more useful: the analogy that finally made it click for me.
The library analogy: Imagine you are a brilliant researcher, but you are only allowed to answer questions from memory - no books, no internet, no notes. You will get a lot right, but you will also confidently fill gaps with things that sound right but are not. Now imagine you are the same researcher, but this time you have access to a library. Before you answer any question, you go to the library, find the most relevant pages from the most relevant books, bring those pages to your desk, and answer the question using what you can see right in front of you. RAG turns the AI from the first researcher into the second. The library is the knowledge base. The retrieval system is how it finds the right pages.
Here are the three steps, in order:
STEP 1: THE QUERY ARRIVES
A user asks a question: 'What does Section 4.2 of our software agreement say about data ownership?' The system takes this query and converts it into a numerical representation (a vector) that captures the meaning of the question — not just the keywords.
STEP 2: RETRIEVAL - FINDING THE RIGHT PAGES
The system searches a vector database - a library of pre-processed documents - for the content most semantically similar to the query. It does not search by keyword matching. It searches by meaning. It finds Section 4.2 of the relevant agreement, pulls the exact text, and passes it to the language model along with the original question.
STEP 3: GENERATION — ANSWERING FROM REAL TEXT
The language model now has two things: the original question, and the retrieved text from the document. It generates an answer grounded in that specific retrieved content, not from its training data. The response is accurate, specific, and can cite the exact source.
The critical difference from standard AI: in step 3, the model is reading real text that was just retrieved, not generating from statistical memory. This is why RAG dramatically reduces hallucinations - the model has the actual answer in front of it, just as a human would when reading a document before responding.
Technical note (skip if you don't need it): The vector database stores documents as numerical representations called embeddings. These embeddings capture semantic meaning, so 'data ownership policy' and 'who owns our data' will retrieve the same relevant document even though they use different words. This is why RAG retrieval is far more powerful than keyword search.
RAG vs Fine-Tuning vs Prompt Engineering - What's the Difference?
These three terms come up together constantly in 2026, and the confusion is understandable because they all aim at the same goal: making AI more useful for specific tasks. They solve very different problems.
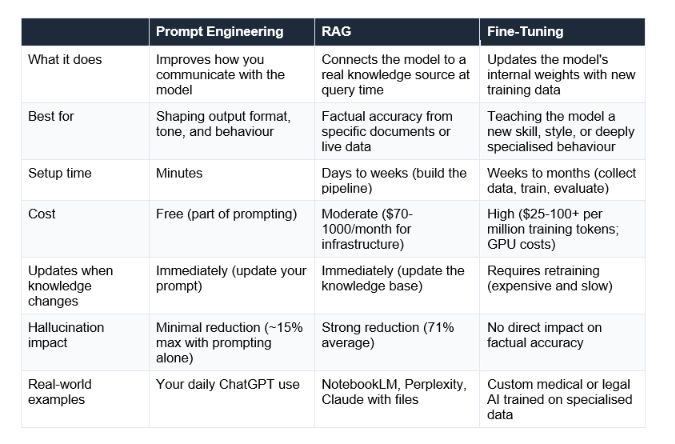
The decision framework from the field in 2026 is clear: always start with prompt engineering, add RAG when you need real-world knowledge accuracy, and only use fine-tuning when you need to change how the model behaves rather than what it knows.
More than 70% of production AI systems in 2026 use RAG as their default approach, according to DeveloperBazaar's enterprise research. Fine-tuning is reserved for genuinely specialised requirements. The industry has largely settled on this order of operations — and it is the same order of operations that makes the most sense for individual users learning AI.
Real Examples of RAG in Products You Already Use
This is the section I think is most important for everyday users. RAG is not an abstract research concept. It is the technique running inside specific tools millions of people use every day in 2026.
NotebookLM (Google)
NotebookLM is a closed RAG system. You upload your own documents — PDFs, Google Docs, YouTube video transcripts, web pages — and NotebookLM builds a knowledge base from exactly those sources. When you ask questions, it retrieves from your documents only. It will not hallucinate facts from the internet because it is grounded exclusively in what you gave it. DigitalOcean's 2026 analysis describes it precisely: 'This closed retrieval augmented generation system significantly reduces hallucinations and ensures every response is backed by specific citations from your documents.'
I have used NotebookLM to analyse 20 research papers simultaneously — asking questions that would have taken hours to answer manually, getting answers with citations pointing to the exact paragraph in the exact paper. That is RAG working for a real task.
Perplexity AI
Perplexity is an open-web RAG system. When you ask a question, it queries the live web, retrieves the most relevant current pages, and uses that retrieved content to generate a cited, grounded answer. This is why Perplexity can answer questions about events that happened this week — it retrieves current information rather than relying on training data with a cutoff date. Every answer comes with citations so you can verify the source.
Claude with Document Upload
When you upload a PDF or a document to Claude and ask questions about it, Claude uses RAG-like retrieval over that document's content. The 1M token context window means Claude can often fit the entire document directly into its working memory, creating a form of direct grounded generation — an advantage over systems that chunk large documents and retrieve only parts. Claude Projects extends this further, letting you build a persistent knowledge base that is automatically available across multiple conversations.
ChatGPT with Web Search
When ChatGPT's web browsing tool is active and searches the internet before answering, it is implementing a form of RAG. It retrieves current web content and uses that content to ground its response, supplementing its training data with live information.
The pattern across all these products: every AI tool that gives you sourced, accurate answers from specific documents or live data is using RAG. The technique is not optional at this point — it is the architecture that makes AI reliably useful rather than occasionally brilliant.
How Much Does RAG Actually Reduce Hallucinations?
I want to give you the real numbers here, not just 'RAG reduces hallucinations significantly.' The data from 2026 is specific and worth understanding.

The most important number is the retrieval grounding figure: RAG-based retrieval grounding reduces hallucination rates by 75-90% in controlled benchmarks, making it by far the most effective single intervention against hallucinations — outperforming all prompt-only mitigations, which cap at around 15% reduction according to April 2026 benchmark data.
But the legal domain finding from Stanford deserves equal attention: even with RAG enabled, legal AI tools still hallucinate in 17-33% of queries. RAG dramatically reduces hallucinations — it does not eliminate them. The AI is still generating text. It can still misread the retrieved content, fail to retrieve the right content, or encounter retrieval failures that cause it to fall back on training data. In high-stakes domains like medicine and law, human verification remains essential even in well-built RAG systems.
Why RAG Matters for Beginners to Understand
You might be thinking: I'm not building AI systems. Why does RAG matter to me?
Three reasons.
1. It Explains Why Some AI Tools Are More Accurate Than Others
When Perplexity gives you a sourced, accurate answer and ChatGPT (without web search enabled) gives you a confident guess, the difference is RAG. When NotebookLM accurately summarises your PDF and a basic chatbot hallucinates details about it, the difference is RAG. Understanding this architecture helps you choose the right tool for the right task - a choice that matters more than which model you use.
2. It Teaches You the Most Important Prompting Trick
Even without a formal RAG system, you can apply the core principle of RAG in your everyday AI use: paste your documents directly into the chat rather than asking the AI to recall things from memory. When you upload a report and ask Claude to analyse it, you are doing manual RAG. The model has the actual text in front of it. Hallucination rates drop to near zero on the specific document you uploaded. This single habit — paste real text, ask about real text — is one of the highest-leverage changes a beginner can make.
3. It Is the Architecture Behind the AI Tools That Will Matter Most
The AI tools that will have the most practical impact on everyday knowledge work in the next 3-5 years are those that let you work with your own knowledge bases — your documents, your research, your notes. All of those tools are built on RAG. Understanding RAG means understanding why these tools work, what their limitations are, and how to use them intelligently rather than blindly trusting every response.
What RAG Cannot Do (Honest Limitations)
I want to close the technical section with the honest list, because understanding the limitations of RAG is what separates careful AI users from overconfident ones.
RAG only knows what you give it. The quality of a RAG system is entirely limited by the quality and completeness of the knowledge base it retrieves from. Garbage in, garbage out. An AWS customer cited in a 2026 case study spent 120 hours tuning their RAG system before getting a 70% drop in incorrect answers — the bottleneck was data quality, not the AI.
Retrieval can fail. Industry analysis in 2026 shows that when RAG fails, the failure point is retrieval 73% of the time — not the generation step. The system retrieves the wrong content, and the AI generates a confident but wrong answer using that incorrect context. Naive RAG pipelines fail at retrieval approximately 40% of the time.
'Lost in the middle' applies to RAG too. When large amounts of content are retrieved, models recall information from the beginning and end of the retrieved context better than information in the middle. Careful chunking and retrieval design is required to mitigate this.
RAG adds latency. The retrieve-then-generate pipeline takes longer than a direct generation. For applications requiring sub-100ms responses, RAG pipelines need specific optimisation or architectural alternatives.
It does not teach the model new skills. RAG gives the model knowledge it does not have. It does not change how the model reasons, writes, or behaves. For behavioural changes — a specific writing style, a domain-specific reasoning approach — fine-tuning is still required.
My honest take on RAG: It is the most important AI reliability technique of 2026 and the right default approach for any AI system that needs to work with specific, real-world information. But it is not magic. It is a well-engineered retrieval system. The quality of the retrieval determines the quality of the generation. Build the retrieval right, and RAG is transformative. Build it carelessly, and it gives you confident wrong answers with citations.
Frequently Asked Questions
Q: What is RAG in AI? (Simple definition)
RAG stands for Retrieval-Augmented Generation. It is a technique that connects an AI language model to an external knowledge source — documents, databases, web pages — at the moment a question is asked. Instead of generating an answer from its training data alone, the model first retrieves relevant information from that knowledge source, then generates an answer grounded in what it retrieved. This dramatically reduces hallucinations and allows AI to answer accurately about specific documents, recent events, and proprietary data it was never trained on.
Q: What is the difference between RAG and fine-tuning?
RAG gives the model knowledge it can access at query time by retrieving from a database. Fine-tuning updates the model's internal weights by training it on new data, baking knowledge or behaviour directly into the model. Use RAG when you need accurate answers from specific documents or real-time data — it is faster to set up, easier to update, and more cost-effective for knowledge tasks. Use fine-tuning when you need to change how the model behaves: its writing style, reasoning approach, or deep specialisation in a narrow domain. In 2026, the standard advice is: prompt engineering first, add RAG when you need knowledge accuracy, reserve fine-tuning for behavioural specialisation.
Q: Does NotebookLM use RAG?
Yes. NotebookLM is a closed RAG system built by Google. You upload your own sources — PDFs, Google Docs, YouTube transcripts, web pages — and NotebookLM retrieves from only those sources when answering your questions. It will not add information from the general internet or its training data. Every answer is grounded in and cited from the specific documents you provided, which is why NotebookLM produces far fewer hallucinations than a standard chatbot for document-specific questions.
Q: How does Perplexity AI work?
Perplexity is an open-web RAG system. When you ask a question, Perplexity searches the live web, retrieves the most relevant current pages, and uses that retrieved content to generate a cited answer. This is why Perplexity can answer questions about recent events — it retrieves current information from the web rather than relying on its training data. Every Perplexity answer includes citations so you can verify the source material.
Q: Does RAG eliminate hallucinations?
No. RAG dramatically reduces hallucinations — by approximately 71% compared to standard language models, according to 2026 research — but it does not eliminate them. The AI can still misread retrieved content, fail to retrieve the right content, or produce errors when retrieval fails. In legal domain queries, Stanford researchers found that RAG-powered legal AI tools still hallucinate in 17-33% of cases. RAG makes AI significantly more reliable. It does not make it perfect. In high-stakes domains, human verification remains essential.
Q: What is a vector database and why does RAG need one?
A vector database stores documents as numerical representations called embeddings, which capture the meaning of text rather than just its keywords. When a query arrives in a RAG system, it is converted into a matching numerical format, and the vector database finds the most semantically similar stored content — meaning 'data ownership policy' and 'who owns our data' will retrieve the same relevant document even though they use different words. RAG needs a vector database because keyword search alone is not precise enough to reliably find the most relevant content. Popular vector databases include Pinecone, Weaviate, Chroma, and pgvector.
Q: Can I use RAG without building a technical system?
Yes — you are already doing a simplified version of RAG every time you paste a document into Claude, ChatGPT, or Gemini and ask questions about it. When you upload a PDF and the AI answers questions from that specific document, you have manually provided the 'retrieval' step. This dramatically reduces hallucinations on the specific document. Tools like NotebookLM, Perplexity, and Claude Projects provide the full RAG pipeline without requiring any technical setup. Building a production RAG system requires engineering, but benefiting from RAG does not.
Q: Why is RAG better than just making the context window bigger?
Larger context windows are useful, but they do not solve the same problem as RAG. A large context window lets you give the model more information in a single conversation. RAG gives the model a searchable, dynamic knowledge base it can retrieve from on demand. The distinction matters because: (1) context windows still have limits — even 1M token windows cannot hold entire enterprise knowledge bases; (2) RAG retrieves only the most relevant information, keeping the context focused and reducing 'lost in the middle' accuracy problems; (3) RAG knowledge bases can be updated instantly without changing the model, while anything in the context window must be re-loaded each conversation.
Recommended Articles
The natural next reads from this concept:
RAG is the technique behind AI that actually works. Now learn it in 5 minutes.
The Unrot RAG course — 'RAG: Stop Hallucinations' — walks through the concept, the architecture, and real examples without requiring any coding background. Free in the app.
app.unrot.co → Intermediate Path → RAG: Stop Hallucinations
References
FreeAcademy.ai (2026). RAG vs Fine-Tuning vs Prompt Engineering. Decision framework: prompt engineering first, RAG for knowledge, fine-tuning for behaviour.
AWS (2026). What Is RAG? Official Amazon Web Services explanation of retrieval-augmented generation.
ATNO for GenAI (Medium, March 2026). Fine-Tuning vs RAG vs Prompt Engineering: When to Use What.
Published on Unrot.co | 18th May
.png&w=3840&q=75)
.png&w=3840&q=75)