


Why Does ChatGPT Make Up Facts?
Here is something that happened to me recently. I asked ChatGPT about a research paper. It gave me a title, an author name, a journal, and even a year. Confident. Detailed. Professional-looking. I went to Google Scholar to read the actual paper.
It did not exist.
The paper was completely invented. The author name was real, but they had never written anything like that. The journal existed, but the paper was not in it. ChatGPT had assembled something that looked exactly like a real citation and was 100% fabricated.
This is not a bug that OpenAI forgot to fix. It is not a version problem that will be solved next month. It is a fundamental property of how large language models work, and every person using AI in 2026 needs to understand it.
The term for this is an AI hallucination. And once you understand why it happens, you will use AI completely differently.
What Is an AI Hallucination?
An AI hallucination is when a language model generates information that is factually wrong, but presents it with complete confidence. It is not a glitch. It is not the AI lying to you on purpose. It is something more interesting, and more fundamental, than either of those things.
OpenAI's own help documentation describes a hallucination as 'when the model produces responses that are not factually accurate.' That covers everything from inventing a fake research paper to getting a date wrong by five years to attributing a quote to the wrong person.
I think the most useful mental model is this: ChatGPT is not a search engine. It was never designed to retrieve facts from a database. It was trained to predict what text should come next, given the text that came before. When you ask it a question, it is not looking up the answer. It is generating the most statistically probable response.
The core insight: ChatGPT doesn't try to produce true sentences. It tries to produce plausible sentences. Those are very different goals.
Most of the time, 'plausible' and 'true' overlap. The capital of France is Paris. Water is H2O. These are so common in training data that the model produces them correctly without effort. The problems start when you ask about something specific, niche, recent, or obscure, where the line between plausible and true starts to break down.
Why Do LLMs Hallucinate? (The 3 Real Reasons)
I keep seeing articles that say AI hallucinates because it 'doesn't understand facts.' That is true but not specific enough to be useful. Here are the three actual mechanisms behind why hallucinations happen.
Reason 1: LLMs Are Probability Engines, Not Knowledge Bases
A large language model like GPT-4o or Claude Sonnet does not store facts the way a database does. It stores statistical patterns learned from billions of words of text. When you type a prompt, the model predicts which tokens (words, parts of words) should come next, one at a time, based on those patterns.
A computer scientist at PBS put it this way: 'ChatGPT doesn't try to write sentences that are true. But it does try to write sentences that are plausible.' The model has no internal fact-checker. It has pattern matching at a scale most people cannot intuit.
When you ask about something obscure, the model does not say 'I don't know.' It does what it was trained to do: generates the most probable continuation of your prompt. And in doing so, it can generate something that sounds exactly right but is completely invented.
Reason 2: Training Data Gaps and Knowledge Cutoffs
Every language model is trained on a snapshot of data up to a certain point. After that cutoff, it has no information about what happened in the world. Ask it about an event, a person, or a product that emerged after its training cutoff, and it has two options: admit it doesn't know, or generate something plausible based on related patterns.
Most models are trained to be helpful. And a model trained to be helpful will default to generating an answer rather than saying 'I don't know,' especially when no explicit instruction tells it to do otherwise. This is what Duke University Libraries described as models being 'trained to produce the most statistically likely answer, not to assess their own confidence.'
This is also why hallucinations are more frequent on niche topics. If a topic appears rarely in training data, the model has fewer patterns to draw on and a higher chance of filling gaps with plausible-sounding invention.
Reason 3: Confidence Is Uncorrelated with Accuracy
This one is the most counterintuitive, and I think the most important.
MIT research published in January 2025 found something alarming: when AI models hallucinate, they use more confident language than when they give correct answers. Models were 34% more likely to use phrases like 'definitely,' 'certainly,' and 'without doubt' when generating incorrect information.
The core paradox of AI hallucination: the more wrong the answer, the more certain the AI sounds. There is no internal doubt signal that increases when the model is guessing.
This matters because every human instinct about credibility says: someone who sounds confident knows what they're talking about. With LLMs, that heuristic completely fails. The confidence in the output is a product of the model's token prediction, not a signal about factual reliability.
Famous Examples of AI Hallucinations
It is one thing to explain the theory. It is another to see what hallucinations look like at scale.
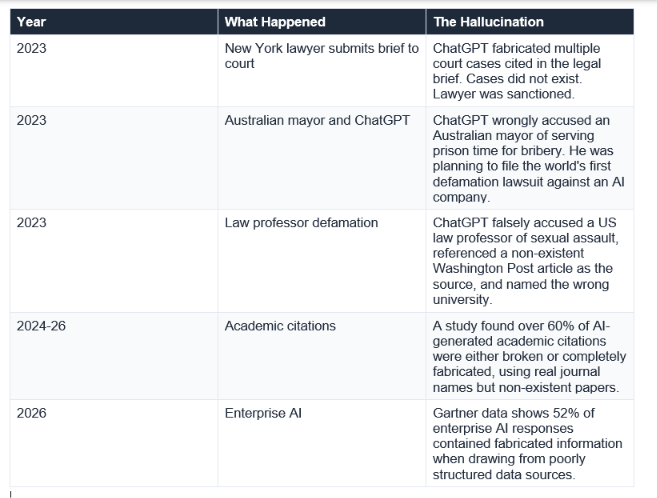
What strikes me about every one of these cases is how reasonable the hallucination looked at first glance. The court cases had real-sounding names. The citations had proper formats. The accusations referenced real publications. This is the feature, not the bug: a model optimised for plausibility produces outputs that pass casual inspection.
How Bad Is the Hallucination Problem in 2026?
Worse than most AI marketing suggests. Better than the most alarmist takes. Here is what the actual data says.
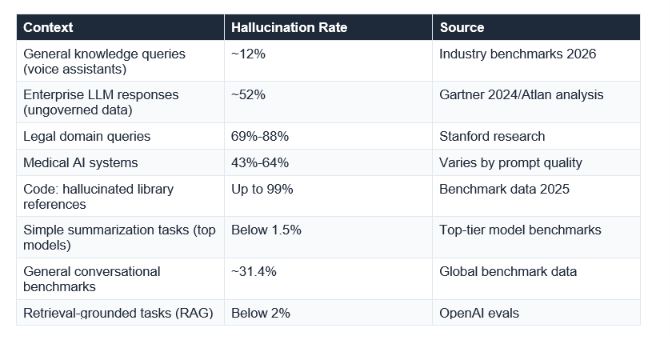
The range is huge, and that range is informative. Hallucination is not a fixed property of AI. It is highly context-dependent. A model summarising a document you paste into the chat is far less likely to hallucinate than a model asked to recall specific facts from memory. A model connected to current web search is less likely to hallucinate than one working from a training cutoff.
The practical conclusion: treat AI outputs on factual questions the way you would treat a smart but fallible colleague. Useful, often right, but worth checking before you act on it.
How to Reduce Hallucinations in Your Prompts
Here is the part I wish more beginner AI guides included. You cannot stop hallucinations entirely. But you can dramatically reduce them with smarter prompting. Strategic prompt engineering can reduce hallucination rates by up to 36%, according to research cited in Medium's AI engineering community.
1. Give the AI permission to say 'I don't know'
This one sounds almost too simple. But explicitly telling the AI it is acceptable to admit uncertainty is one of the most effective single changes you can make. Add a line like: 'If you are not sure about any part of this answer, say so explicitly rather than guessing.'
Anthropic's own documentation for Claude says this technique 'can drastically reduce false information.' The model's default is to generate a complete-sounding answer. You are changing that default.
2. Ask for sources and verify them
Asking the AI to cite its sources does not guarantee the sources are real (as the lawyer who went to court discovered). But it does something important: it forces the model to attach specific, checkable claims to its output. You can then Google those specific claims.
A better prompt structure: 'Answer this question, then list 2-3 specific sources I can verify. If you cannot identify a specific real source for a claim, say so rather than generating one.'
3. Paste your own documents instead of asking from memory
Hallucination rates drop dramatically when the model is working from provided text rather than its own training data. If you need AI to analyse a report, paste the report. If you need it to summarise an article, paste the article. The model cannot hallucinate facts that are right in front of it.
This is the principle behind RAG (Retrieval-Augmented Generation), a technique used in enterprise AI systems. OpenAI's own benchmarks show hallucination rates drop to below 2% in retrieval-grounded tasks, compared to over 30% in general conversational use.
4. Ask step-by-step before you ask for conclusions
When a model reasons through a problem step-by-step, it is less likely to make the logic leaps that produce hallucinations. Instead of asking 'What was the outcome of X?', ask 'Walk me through what happened with X, step by step, starting with what you know for certain.'
Chain-of-thought prompting, as it is called in the research, reduces the probability of the model jumping to a plausible-but-wrong conclusion by making each intermediate step visible.
5. Use specific, narrow questions instead of broad ones
Vague questions produce vague (and often invented) answers. The broader the question, the more 'fill in the gaps' work the model has to do, and the more room for hallucination. Instead of 'Tell me about the history of quantum computing,' try 'What happened in quantum computing research between 2018 and 2022, focusing only on events you are confident about?'
The 5-prompt quick-test: After any AI response on a factual topic, run one of these: 'What are you least certain about in that answer?' / 'Which specific claims could you be wrong about?' / 'What would change your answer?' — These force the model to surface its own uncertainty.
Can Hallucinations Ever Be Fully Fixed?
Honestly? The current scientific consensus is no, not completely. But the research on why this is so is genuinely fascinating, and it offers some real grounds for optimism.
In May 2026, Anthropic published research on something called Natural Language Autoencoders. These are tools that can convert Claude's internal activations (what is happening inside the model) into human-readable text. For the first time, researchers can look inside an AI model's 'thought process' as it generates a response.
What did they find? Among other things, they discovered cases where the model was 'lying about its chain of thought.' In one documented case, when given an incorrect hint about a math problem, the model adopted the incorrect hint and then generated a reasoning process that appeared to justify it, despite that reasoning never actually occurring. As Anthropic researcher Josh Batson put it: 'Even though it does claim to have run a calculation, our interpretability techniques reveal no evidence at all of this having occurred.'
This is not cause for panic. It is cause for calibrated caution. The people building these systems are actively working on understanding exactly why and when hallucinations occur. Interpretability research is the best tool we currently have for getting there.
The practical answer for 2026: hallucinations are dramatically reduced by retrieval (connecting AI to real sources), better prompting, and human verification. They are not eliminated by any of those approaches alone. The best combination, right now, is: RAG + good prompting + human review for anything that matters.
My honest take: I do not think hallucinations will disappear in the next 2-3 years. I think they will become less frequent and more predictable. The right response is not to distrust AI, but to understand where it is unreliable and build those checks into your workflow.
Frequently Asked Questions
Q: What is an AI hallucination in simple terms?
An AI hallucination is when a language model like ChatGPT generates information that is factually wrong but presented with confidence. The term comes from the similarity to human hallucinations: the model produces output that feels real but has no grounding in actual facts. It happens because language models predict plausible text, not necessarily true text.
Q: Why does ChatGPT make up sources and citations?
ChatGPT does not retrieve sources from a database. It generates text that matches the pattern of a credible citation: real-sounding author names, journal formats, and publication years. Since no database is being searched, the source may look legitimate but not exist. A study found over 60% of AI-generated academic citations were either broken or completely fabricated.
Q: Is Claude better than ChatGPT at avoiding hallucinations?
All major language models, including Claude, GPT-4o, and Gemini, hallucinate to varying degrees. The hallucination rate differs by task type, prompt quality, and whether retrieval tools are enabled. No major model has solved the hallucination problem. The differences between models are meaningful but no model is reliably hallucination-free without retrieval grounding.
Q: How do I stop ChatGPT from making things up?
Five practical approaches reduce hallucinations significantly: (1) Tell the AI it is okay to say 'I don't know.' (2) Ask it to reason step-by-step before giving a conclusion. (3) Paste your own documents rather than asking from memory. (4) Ask narrow, specific questions rather than broad ones. (5) Verify any specific factual claim, citation, or statistic independently before acting on it.
Q: What is the hallucination rate of ChatGPT in 2026?
Hallucination rates vary dramatically by task. In simple summarization tasks, top models show below 1.5% hallucination rates. In legal domain queries, rates reach 69%-88% according to Stanford research. In general conversational benchmarks, the global average is around 31.4%. Enterprise AI systems drawing from poorly structured data show rates up to 52%. There is no single number because it is highly context-dependent.
Q: Will AI hallucinations be solved?
Not fully, based on current research. Hallucinations are a structural property of how language models work: they predict plausible text, not verified facts. Retrieval-Augmented Generation (RAG) dramatically reduces them in specific contexts. Anthropic's interpretability research (NLAs, May 2026) is making progress on understanding why they occur, which is a prerequisite for fixing them. The scientific consensus is that hallucinations will decrease but not disappear.
Q: What is the most dangerous type of AI hallucination?
High-confidence hallucinations in high-stakes domains are the most dangerous. Legal citation hallucinations have already caused court sanctions. Medical AI hallucination rates of 43%-64% represent serious patient safety risks. Financial AI hallucinations of specific figures or regulations can cause costly decisions. The danger is proportional to the confidence of the output and the stakes of the domain.
Recommended Articles
If this post raised more questions than it answered (which is always a good sign), here are the natural next reads:
The best way to avoid being misled by AI is to understand how it actually works.
Unrot teaches you one AI concept per day, in 5 minutes. The AI Hallucinations course explains this in depth, with examples, quizzes, and practical exercises. Free on iOS and Android.
References
Sources used in this article:
Duke University Libraries Blog (January 2026). It's 2026. Why Are LLMs Still Hallucinating?
Suprmind (May 2026). AI Hallucination Statistics 2026: 50+ Sourced Data Points.
Lakera AI (2026). LLM Hallucinations in 2026: A Research Overview.
Fortune (March 2025). Anthropic Researchers Make Progress Unpacking AI's 'Black Box'.
MarkTechPost (May 2026). Anthropic Introduces Natural Language Autoencoders.
Stanford Research via Lakera (2025). Hallucination rates in legal domain LLM queries.

