What Is NLP? Natural Language Processing Explained Simply
Right now, somewhere in India, a student is asking Google a question in Hindi. A customer is complaining about a late delivery in a Swiggy chat. A banker's document is being scanned for fraud. And millions of WhatsApp messages are being filtered for spam. None of these things would work without NLP.
Natural language processing is not a new idea. Researchers have been working on it since the 1950s. But it went from an obscure academic field to the technology powering almost everything you do with your phone in less than a decade. ChatGPT, Google Translate, Grammarly, autocorrect, voice search - all of it runs on NLP.
Most explanations of NLP either get too technical immediately or stay too vague to be useful. I want to fix that. By the end of this post, you will understand exactly what NLP is, how it works at a conceptual level, what the key techniques are, and where it shows up in your daily life, whether you are a student, a working professional, or just someone curious about AI.
What Is NLP? The Simple Answer
Natural language processing (NLP) is the branch of artificial intelligence that deals with teaching computers to understand, interpret, and generate human language. It is a subfield of AI that sits at the intersection of computer science, linguistics, and machine learning.
The key word is natural. Human language - the kind you speak, text, and write - is unstructured, ambiguous, contextual, and constantly evolving. Computers are built to handle precise, structured instructions. NLP is the bridge between those two worlds.
According to Stanford HAI, NLP combines computational linguistics, machine learning, and deep learning to process text and speech data for various tasks. According to IBM (2026), NLP is already part of everyday life for many people, powering search engines, chatbots, voice-operated GPS systems, and question-answering digital assistants like Amazon's Alexa, Apple's Siri, and Microsoft's Cortana.
The global NLP market was valued at approximately USD 36.8 billion in 2025 and is projected to grow to USD 45.74 billion in 2026 at a CAGR of nearly 20%, according to Fortune Business Insights. That is not a niche academic field. That is the infrastructure of the modern internet.
Why Language Is Hard for Computers
Before we explain how NLP works, it helps to understand why language is so difficult for machines in the first place. Computers are deterministic. Give them the same input and they produce the same output. Language does not work like that.
Consider the sentence: 'I saw a man on a hill with a telescope.' Who has the telescope? The man? You? Is the telescope on the hill? This sentence has at least five valid grammatical interpretations. A human reader resolves this instantly using context, world knowledge, and experience. A computer has none of that by default.
Or consider sarcasm: 'Oh great, another Monday.' The words are positive. The meaning is negative. A system that reads words without understanding context will get this completely wrong.
Then there is ambiguity in word meanings. 'Bank' can mean a financial institution or the side of a river. 'Bark' can be a dog's sound or tree covering. The same word, different meanings depending entirely on surrounding context. Language is full of this.
Finally, language changes. Slang evolves. New words appear. Old words shift meaning. A system trained on text from 2020 will miss references that emerged in 2024. This makes NLP an ongoing engineering problem, not a solved one.
My take: this is why NLP is genuinely one of the harder problems in computer science. The fact that it works as well as it does in 2026 represents decades of accumulated breakthroughs, not a single invention.
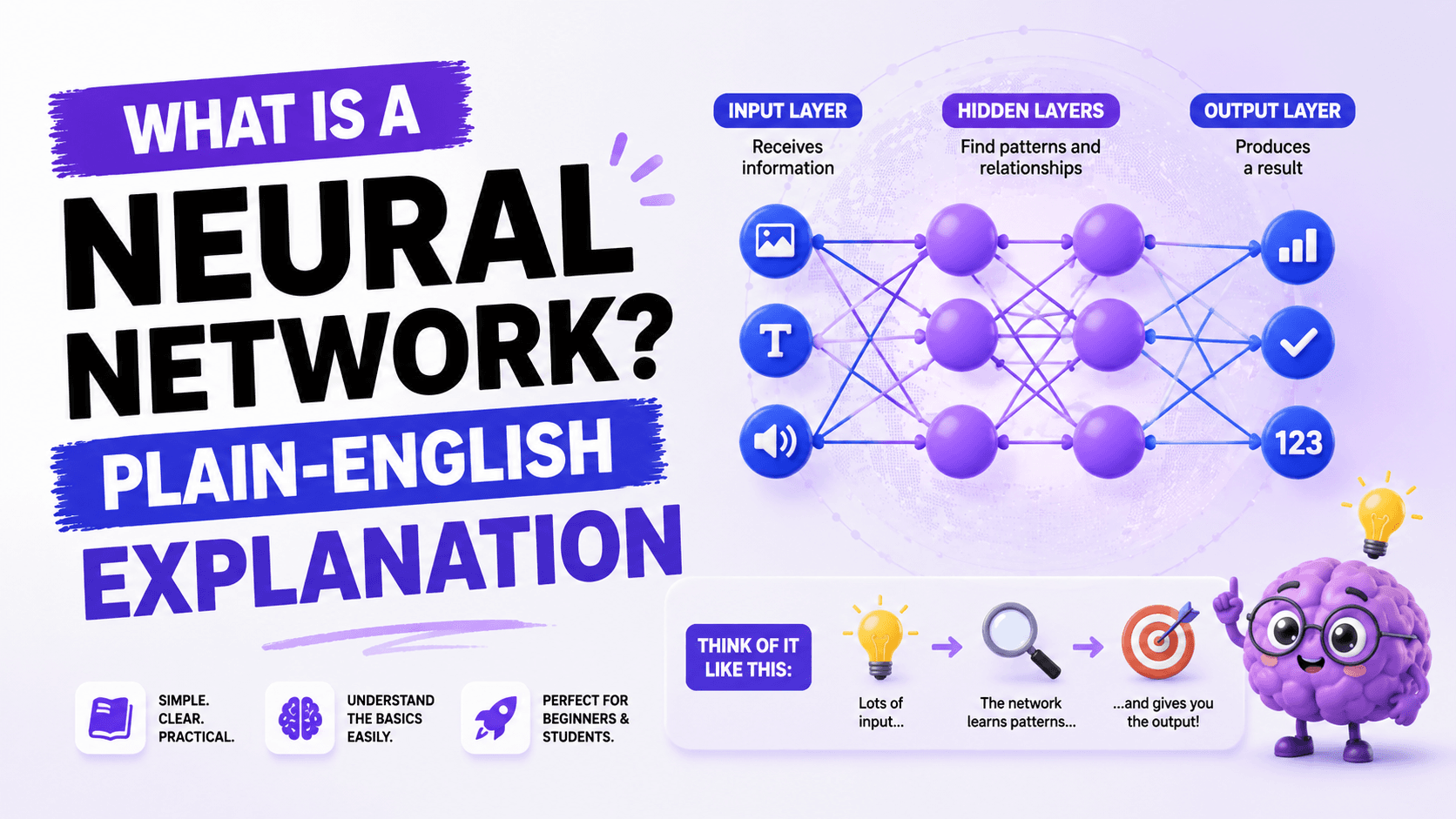
How NLP Works: The 5-Step Pipeline
When a piece of text enters an NLP system - whether it is a search query, a customer review, or a chat message - it typically goes through a processing pipeline. The exact steps vary by application, but the core sequence looks like this.
Step 1: Text acquisition
The system receives raw text or audio. If it is audio (like a voice assistant), speech recognition converts the sound into text first. This step is called automatic speech recognition (ASR) and is technically separate from NLP but closely related.
Step 2: Preprocessing and tokenization
Raw text is cleaned and broken into smaller units called tokens. Tokenization splits a sentence into individual words or sub-words that the model can process. 'I want to learn NLP.' becomes [I, want, to, learn, NLP, .]. The system also removes noise: extra spaces, punctuation where irrelevant, and inconsistent capitalisation.
Stopword removal strips out words like 'is', 'the', and 'and' that carry little meaning for many tasks. Lemmatization reduces words to their base form: 'running', 'runs', 'ran' all become 'run'. These steps help the model focus on meaningful content.
Step 3: Text representation
Computers cannot process words directly. They work with numbers. So text must be converted into numerical form - vectors. Early NLP systems used simple word counts or TF-IDF (term frequency-inverse document frequency). Modern systems use embeddings: dense numerical vectors that capture meaning and context. The word 'king' ends up close to 'queen' in vector space. 'Delhi' ends up close to 'Mumbai'. These relationships encode semantic knowledge.
Our post on what AI embeddings are explains this concept in more depth if you want to go further.
Step 4: Model processing
The numerical representation passes through a model trained to perform a specific task: translate the text, classify its sentiment, identify named entities, answer a question. The model's architecture depends on the task. Modern NLP almost universally uses transformer-based neural networks, which we cover below.
Step 5: Output generation
The model produces a result: a translated sentence, a sentiment label (positive/negative/neutral), an answer, a summary, or generated text. For generation tasks, the system converts the model's numerical outputs back into human-readable language.
NLU vs NLG: The Two Sides of NLP
NLP is often split into two overlapping subfields. Understanding the difference is one of those conceptual unlocks that makes everything else make sense.
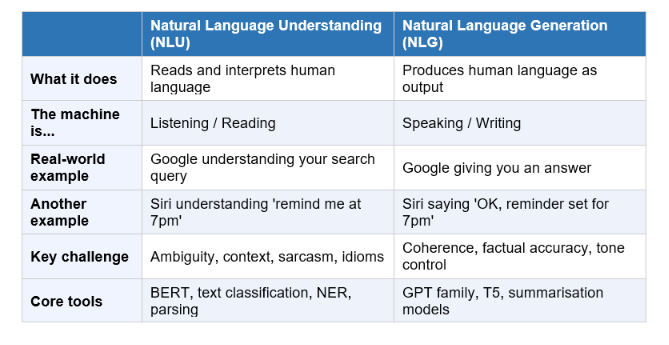
Most AI products use both. When you ask ChatGPT a question, NLU processes what you mean. NLG produces the response. When Google Translate reads Hindi and outputs English, NLU reads the source, NLG writes the target.
The reason this distinction matters is that NLU and NLG have different failure modes. NLU fails when it misinterprets your intent: the system does the wrong thing because it read you incorrectly. NLG fails when the output is incoherent, factually wrong, or tonally off, even if the input was understood correctly. ChatGPT's hallucination problem is primarily an NLG failure.
The 8 Core NLP Tasks You Should Know
NLP is not one thing. It is a collection of specific tasks, each with its own techniques and benchmarks. Here are the eight you will encounter most often.
1. Text classification
Assigning a label to a piece of text. Is this email spam or not? Is this product review positive, negative, or neutral? Is this news article about politics, sport, or technology? Text classification is the foundation of spam filters (Google Gmail), content moderation (Instagram, YouTube), and customer feedback analysis at every major company.
2. Sentiment analysis
A specific type of classification focused on detecting the emotional tone of text. Positive, negative, neutral. Some systems go further: joy, anger, fear, surprise, sadness. According to Mordor Intelligence (2026), banking, financial services, and insurance hold 21.1% of the NLP market share, with sentiment analysis being one of their primary use cases for monitoring social media and customer complaints.
3. Named entity recognition (NER)
Identifying specific real-world entities in text and labelling them by type. In the sentence 'Sundar Pichai announced Google's new model in San Francisco on Tuesday', NER identifies Sundar Pichai as a person, Google as an organisation, San Francisco as a location, and Tuesday as a date. NER powers news aggregation, document processing, legal tech, and financial research.
4. Machine translation
Automatically converting text from one language to another while preserving meaning, context, and nuance. Google Translate, DeepL, and Microsoft Translator are the most visible applications. Google Translate supports over 130 languages as of 2026. The shift from rule-based to neural translation (specifically transformer-based) in 2016 produced a dramatic quality improvement that researchers had not expected to happen so quickly.
5. Question answering
Given a question and a body of text, extract or generate the correct answer. Early systems like IBM Watson (famous for winning Jeopardy! in 2011 against human champions) were based on rule-heavy systems. Modern question answering systems like those powering Google Search's featured snippets and Perplexity AI use transformer models fine-tuned on large labelled datasets.
6. Text summarisation
Condensing a long document into a shorter version that retains the key information. Two types: extractive (pulling out key sentences verbatim) and abstractive (generating a new summary in different words). Abstractive summarisation is harder and requires strong NLG. Most AI writing tools, meeting summarisers, and document processors use some form of this.
7. Speech recognition
Converting spoken audio into text. Technically a separate field but deeply integrated with NLP. Every voice assistant starts here. Google's speech recognition, integrated into Android and Google Meet, has achieved word error rates below 5% for clear English audio, according to Google AI research published in 2023.
8. Text generation
Producing coherent, contextually appropriate text from a prompt. This is what ChatGPT, Claude, and Gemini do. The quality of text generation has improved so dramatically since 2018 that it has created entirely new product categories: AI writing assistants, coding copilots, customer service bots, and content generation tools. It has also created new problems: misinformation, academic dishonesty, and AI-generated spam at scale.
How NLP Evolved: From Rules to Transformers
NLP did not arrive fully formed. It went through four distinct eras, each building on the failures of the last.
Era 1: Rule-based systems (1950s to 1980s)
The Georgetown-IBM experiment in 1954 was one of the first demonstrations of machine translation: 60 Russian sentences automatically translated into English using hand-coded rules. Researchers at the time predicted the problem would be solved within five years. They were spectacularly wrong. Rule-based systems could not handle the sheer complexity and ambiguity of language. The ALPAC report in 1966 concluded that machine translation research had failed to deliver results, and funding was dramatically cut.
Era 2: Statistical NLP (1990s to 2010s)
The shift from rules to statistics changed everything. Instead of writing grammatical rules by hand, researchers began training models on large corpora of text, letting them learn statistical patterns. Spam filters became effective. Sentiment analysis emerged. Google's early search ranking algorithms used statistical NLP. The limitation was feature engineering: humans still had to decide which features (word counts, n-grams, syntactic patterns) to feed the model.
Era 3: Deep learning (2010s)
The introduction of deep neural networks allowed NLP systems to learn their own features from raw text, without manual engineering. Word2Vec (introduced by a Google team led by Tomas Mikolov in 2013) showed that words could be represented as dense vectors that captured semantic relationships. LSTMs (long short-term memory networks) and RNNs (recurrent neural networks) enabled sequential processing of text, making translation and language modelling significantly better.
Era 4: Transformers and LLMs (2017 to present)
The 2017 Google Brain paper 'Attention Is All You Need' by Vaswani et al. introduced the transformer architecture and rendered almost everything before it obsolete for language tasks. Transformers process all words in a sentence in parallel (rather than sequentially) and use attention mechanisms to capture relationships between every word and every other word in context. Google's BERT (2018) used transformers for understanding. OpenAI's GPT series used them for generation. By 2020 it was clear that scaling transformer models with more data and more compute produced qualitatively better language understanding and generation across almost every NLP task.
ChatGPT's launch in November 2022 was the public moment when NLP became a mainstream conversation. But the research behind it spans 70 years. If you want to understand what makes ChatGPT work at a technical level, our post on what a large language model is covers the architecture in plain English.
NLP in Your Daily Life: 10 Examples You Already Use
NLP is not something you install or sign up for. It is already running in the tools you use every day. Here are ten places where you are already benefiting from natural language processing.
Autocorrect and predictive text: Every time your phone corrects a typo or suggests the next word, an NLP model is running on-device. Apple's keyboard model and Gboard both use transformer-based language models for prediction.
Google Search: Since 2019, Google has used BERT to understand the meaning behind search queries, not just keyword matching. A search for 'can you get a visa for Brazil as a UK citizen' now returns results about UK citizens specifically, not just any Brazil visa content.
Google Translate: Neural machine translation powered by a transformer model. Supports 133 languages as of 2026. Google processes over 100 billion words of translation per day, according to Google.
Grammarly: Real-time grammar checking, tone detection, and writing suggestions using NLP. Grammarly's models run sentiment analysis, grammatical parsing, and context-aware correction on every sentence you type. Over 30 million people use it daily as of 2025.
Gmail smart reply and compose: Gmail's Smart Reply feature (launched 2017) uses an NLP model to suggest short contextual responses. Smart Compose (launched 2018) predicts the rest of your sentence as you type.
Voice assistants (Siri, Alexa, Google Assistant): Every query goes through speech recognition (audio to text) and then NLP (text to intent and action). Google Assistant handles billions of queries per month across 90 countries and 30 languages.
ChatGPT, Claude, Gemini: These are large language models, a category of NLP system. Every response generated by these tools is produced by a transformer model predicting the most likely next token from a vocabulary of tens of thousands of words. NLP is not just part of what they do. NLP is everything they do.
YouTube and Netflix subtitles: Automatic speech recognition converts spoken audio into captions. NLP models then clean, punctuate, and time-align the text. YouTube generates automatic captions in 16 languages using Google's speech and NLP stack.
Spam filters: Your Gmail spam folder is almost empty because a text classification NLP model has been running quietly since 2004. Google's spam filter blocks approximately 100 million spam emails per day according to Google's published figures.
Customer service chatbots: Every brand chatbot you have interacted with, whether on Zomato, HDFC, or Airtel, uses NLP to understand your query and route it to the right response or human agent. According to IBM (2026), NLP-powered chatbots handle routine customer queries at scale, freeing human agents for complex issues.
NLP vs Machine Learning vs Deep Learning vs LLMs
These four terms are used interchangeably in the media and that is almost always wrong. Here is the precise relationship.

The simplest mental model: NLP is the field. Machine learning is the broader methodology. Deep learning is the specific technique powering modern NLP. LLMs are the most powerful and prominent class of current NLP systems.
A longer explanation of this distinction, including how machine learning sits within the broader AI landscape, is in our post on what machine learning is.
What NLP Cannot Do (Honest Answer)
NLP has made extraordinary progress. It has also been the subject of extraordinary hype. Here is where the honest limits are.
NLP systems do not understand language the way humans do. A transformer model does not know what a dog is. It knows that 'dog' appears near 'bark', 'leash', 'pet', 'puppy', and 'cat' more often than near 'engine', 'algorithm', or 'theorem'. That statistical knowledge is incredibly powerful for many tasks. It is not the same as understanding.
This creates a specific failure mode: confident wrongness. ChatGPT can produce a grammatically perfect, contextually coherent, completely false statement about a medical treatment because the words fit together well statistically, not because the model has verified the facts. This is what researchers call hallucination, and it remains one of the hardest unsolved problems in NLP.
NLP also struggles with rare languages and dialects. The reason English NLP is so strong is the sheer volume of English text used for training. Languages with less digital text (many regional Indian languages, for example) produce dramatically weaker NLP systems because there is less data to learn from. Google Translate's quality for Gujarati or Odia is materially worse than for Spanish or French.
Sarcasm, irony, cultural references, and highly contextual communication remain genuinely difficult. A model trained on formal text will misread casual or regional expression. An NLP system trained on American English will make errors on Indian English idioms and code-switching (mixing English with Hindi mid-sentence, which is the default communication style for hundreds of millions of people).
My honest take: NLP in 2026 is the best it has ever been and simultaneously more limited than most media coverage suggests. Use it as a powerful tool for language tasks where approximate outputs are acceptable and where human review catches errors. Do not deploy it unsupervised in high-stakes domains without an understanding of its failure modes.
Frequently Asked Questions
What is NLP in simple terms?
NLP (natural language processing) is the branch of AI that teaches computers to understand, interpret, and generate human language. It is the technology behind Google Translate, Siri, ChatGPT, spam filters, and autocorrect. According to Stanford HAI, NLP combines computational linguistics, machine learning, and deep learning to process text and speech. In simple terms: NLP is how computers learn to read, write, and listen the way humans do.
What is NLP used for?
NLP is used for machine translation (Google Translate), sentiment analysis (understanding customer reviews), spam detection (Gmail), voice assistants (Siri, Alexa, Google Assistant), chatbots (customer service bots), text summarisation (meeting summarisers like Otter.ai), grammar checking (Grammarly), search engines (Google, Bing), and large language models (ChatGPT, Claude, Gemini). According to Fortune Business Insights (2026), the global NLP market was valued at USD 36.8 billion in 2025 and is growing at nearly 20% annually.
What is the difference between NLP and AI?
AI (artificial intelligence) is the broad field of making machines perform tasks that typically require human intelligence. NLP is a specific subfield of AI focused on human language. All NLP is AI, but not all AI is NLP. Other AI subfields include computer vision (which deals with images), robotics, and reinforcement learning. Think of it as: AI is the country, NLP is one of the states within it.
Is ChatGPT an example of NLP?
Yes. ChatGPT is built on GPT-4 (and GPT-5.5 as of 2026), a large language model developed by OpenAI. LLMs are a category of NLP system. Every word ChatGPT generates is produced by a transformer neural network predicting the next token based on the conversation context. The entire input/output pipeline - reading your message, generating a response - is NLP. ChatGPT is one of the most capable NLP systems publicly available.
What is the difference between NLP and machine learning?
Machine learning is the broader field of systems that learn from data. NLP is a specific application domain within machine learning focused on human language. Most modern NLP systems are built using machine learning techniques, specifically deep learning with transformer architectures. The relationship: machine learning is a method, NLP is a problem domain that uses that method.
What is NLU vs NLP?
NLP is the overall field. NLU (natural language understanding) is a subfield of NLP focused specifically on reading and interpreting human language input - understanding intent, extracting meaning, resolving ambiguity. NLG (natural language generation) is the complementary subfield focused on producing human-readable text output. ChatGPT uses NLU to understand your question and NLG to produce its response. Most NLP systems combine both.
How does NLP work step by step?
A typical NLP pipeline has five stages. First, text acquisition: raw text or converted speech enters the system. Second, preprocessing: text is cleaned and split into tokens (individual words or sub-words). Third, text representation: tokens are converted into numerical vectors (embeddings) that capture meaning. Fourth, model processing: a trained model (typically transformer-based) performs the target task using those vectors. Fifth, output generation: results are converted back into readable text, a label, or an action. The exact pipeline varies by application but the sequence is consistent.
What is an example of NLP in everyday life?
Autocorrect on your smartphone is one of the most ubiquitous NLP applications - an on-device language model predicts what word you intended when you typed something that does not exist in a dictionary. Other everyday examples include: Gmail's spam filter (text classification), Google Search's ability to answer natural questions (NLU + question answering), Google Translate (machine translation), Grammarly (grammar and style analysis), and any chatbot you have interacted with online. If you have used WhatsApp in the last 24 hours, NLP was running in the background checking messages for spam.
What is the difference between NLP and LLMs?
NLP is the broader field of teaching computers to understand and generate language. LLMs (large language models) like GPT-5, Claude Opus 4, and Gemini are a specific, very powerful class of NLP systems. They are transformer-based neural networks trained on massive text corpora with billions or hundreds of billions of parameters. Not all NLP uses LLMs - a spam filter or a simple sentiment analyser can be a much smaller model. But LLMs represent the current state-of-the-art for the most complex NLP tasks: conversation, long-form writing, code generation, and reasoning.
Recommended Reads
• What Is a Large Language Model?
The best time to start learning AI was yesterday. The second best time is right now.
References
• Stanford HAI - What Is Natural Language Processing?
• AWS - What Is Natural Language Processing?
• DeepLearning.AI - Natural Language Processing
• Wikipedia - Natural Language Processing
• Fortune Business Insights - Natural Language Processing
• MarketsandMarkets - Global NLP Market Projected to Grow