What Is a Neural Network? Plain-English Explanation
Every time you unlock your phone with your face, Spotify figures out your next song, or ChatGPT replies to your question, a neural network is running in the background. Neural networks are not a new concept. The idea is nearly 80 years old. But they quietly became the engine behind almost every AI product you use today.
Most explanations of neural networks either go too technical too fast, or stay so abstract they leave you more confused than when you started. I want to fix that. No equations. No jargon walls. Just a clear, honest explanation of what a neural network actually is, how it learns, and why it matters to you right now.
What Is a Neural Network? The Simple Answer
A neural network is a type of machine learning model that learns patterns from data by passing information through connected layers of simple processing units called neurons. The network adjusts the connections between those neurons until its outputs match what it was trained to predict.
Think of it like this. Imagine you show a neural network 100,000 photos of cats and 100,000 photos of dogs, each labelled correctly. At first, the network makes random guesses. It gets most of them wrong. But every time it gets something wrong, it adjusts its internal settings slightly. After millions of adjustments across millions of examples, it learns which visual patterns reliably signal 'cat' versus 'dog'. No one programmed the rules for recognising cats. The network found them on its own.
That self-teaching from examples is the core idea. Traditional software follows explicit instructions written by a human programmer. A neural network writes its own instructions, in a sense, by learning from data.
According to IBM (2026), neural networks are among the most influential algorithms in modern machine learning, underpinning breakthroughs in computer vision, natural language processing, speech recognition, and dozens of other real-world applications.
Where the Idea Came From: The Brain Analogy
The biological inspiration is real, not just a marketing metaphor. Your brain contains roughly 86 billion neurons, each a tiny cell that receives signals from other neurons and either fires or stays quiet depending on the strength of those signals. Neurons are connected by synapses, and the strength of each synaptic connection changes with learning. That is how memories form and skills develop.
In 1943, Warren McCulloch and Walter Pitts at the University of Chicago proposed the first mathematical model of a neuron, showing that simple computational units could perform logical operations. In 1958, Frank Rosenblatt at Cornell introduced the perceptron, the first practical algorithm inspired by that model. The perceptron could learn to classify inputs, a significant milestone at the time.
The analogy is imperfect. Artificial neurons are dramatically simpler than biological ones, and the human brain has structural properties we cannot yet replicate in software. I think it is worth being honest about this: calling them 'neural' networks is partly a branding choice. The mathematics owes more to statistics and linear algebra than to neuroscience. But the core intuition, that connected processing units with adjustable connection strengths can learn, does trace back to biology.
The term artificial neural network (ANN) is technically more precise, but most people just say 'neural network.'
How a Neural Network Is Structured
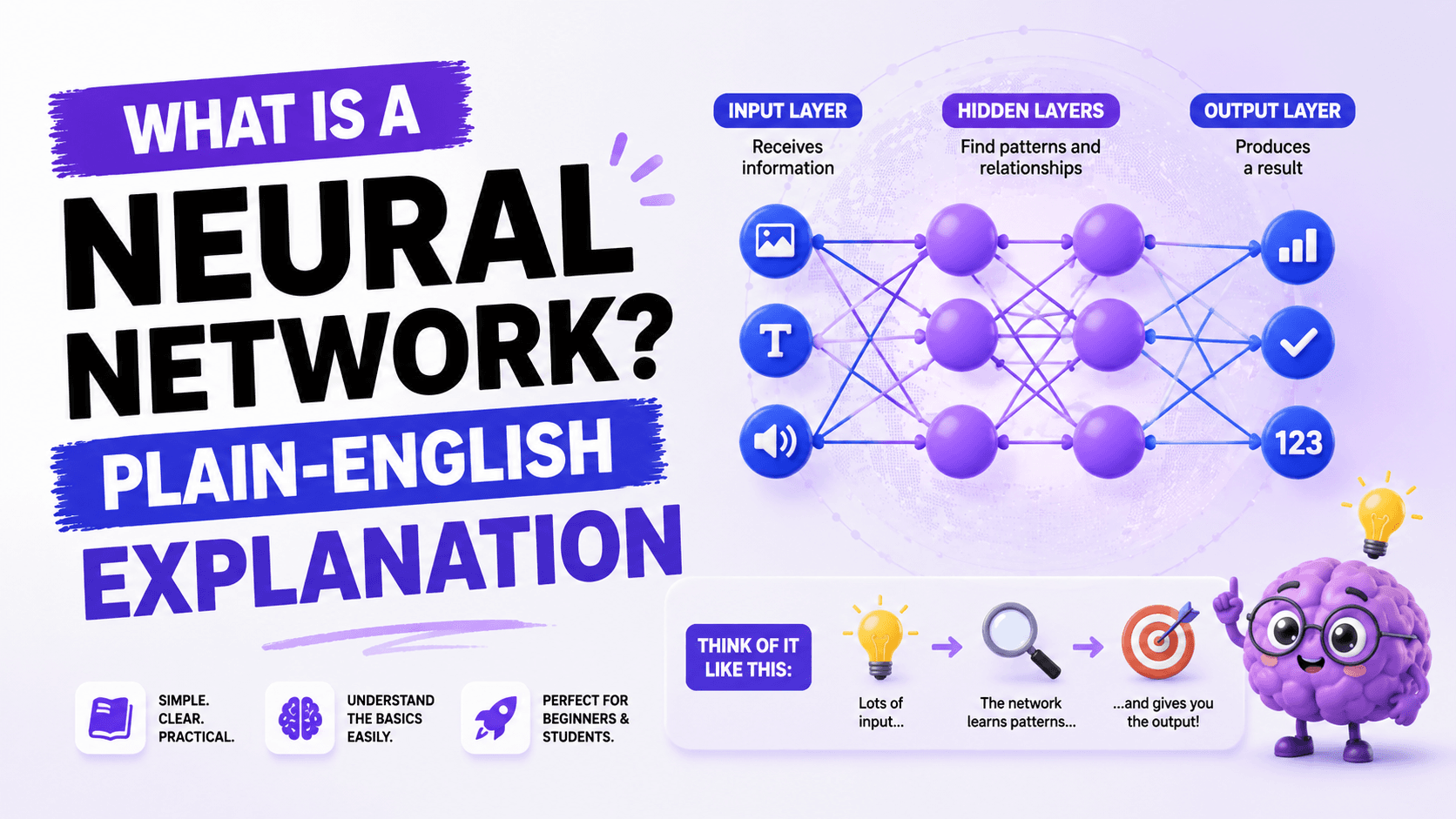
Every neural network has the same basic structure: an input layer, one or more hidden layers, and an output layer. Data enters through the input layer, gets transformed by the hidden layers, and exits as a prediction through the output layer.
The input layer
The input layer receives raw data. If you are training a network to recognise handwritten digits, each pixel in the image becomes one input. A 28x28 pixel image, like those in the famous MNIST benchmark dataset used by Yann LeCun and colleagues at Bell Labs in 1998, produces 784 inputs. Each input is simply a number.
The hidden layers
Hidden layers are where the real processing happens. Each neuron in a hidden layer receives numbers from the previous layer, multiplies each by a weight (a number that reflects how important that input is), adds a bias (a small offset to help the neuron fire at the right threshold), sums everything up, and passes the result through an activation function.
The activation function is what gives neural networks their power. Without it, the whole network would behave like a single linear equation and could only learn simple relationships. Activation functions like ReLU (Rectified Linear Unit, introduced as the dominant modern approach in 2010 by Glorot and Bengio at the University of Montreal) introduce non-linearity, allowing networks to learn complex curved patterns.
Deep neural networks have many hidden layers. The word 'deep' in deep learning literally refers to the depth of the network, measured in layers. Google's AlexNet in 2012, which revolutionised image recognition, had 8 layers. Today's large language models like GPT-4 have hundreds.
The output layer
The output layer produces the final result. For a cat/dog classifier, there might be two output neurons: one for cat probability, one for dog probability. For a language model like Claude or ChatGPT, the output layer produces a probability score for every word in the vocabulary, and the model picks the most likely next word.
How a Neural Network Actually Learns
Learning in a neural network happens through a process called training, which involves three steps repeated millions of times: forward pass, loss calculation, and backpropagation.
In the forward pass, a piece of training data (say, one photo of a cat) passes through the network from input to output. The network produces a prediction. At the start of training, this prediction is essentially random.
Next, the network calculates its error using a loss function. The loss function measures how wrong the prediction was. A loss of zero means perfect prediction. A high loss means the network is badly off.
Then comes backpropagation, short for backward propagation of errors, formalised by David Rumelhart, Geoffrey Hinton, and Ronald Williams in their landmark 1986 paper in Nature. The network works backwards from the output to the input, calculating how much each weight contributed to the error. It then adjusts every weight slightly in the direction that reduces the loss, using an algorithm called gradient descent.
Repeat this process millions of times across millions of training examples, and the network's weights gradually converge on values that produce accurate predictions. The speed at which weights are adjusted is controlled by the learning rate, one of the most important settings (called a hyperparameter) a practitioner has to tune.
My take: Backpropagation is the unsexy workhorse of modern AI. Almost every major AI product you use today was trained with some variant of it. Knowing it exists is enough for a beginner. Knowing the maths is only necessary if you plan to build networks yourself.
The 5 Most Common Types of Neural Networks
Not all neural networks are built the same way. Different architectures are optimised for different data types.
Feedforward networks are the simplest. Data flows in one direction: input to output, no loops. They work well for structured tabular data but struggle with images and text where spatial or sequential relationships matter.
Convolutional neural networks (CNNs), pioneered by Yann LeCun (now at Meta AI) in the 1990s and brought to global attention by AlexNet in 2012, are designed for grid-structured data like images. Convolutional layers scan for local features (edges, textures, shapes) and pass those features forward to deeper layers.
Recurrent neural networks (RNNs) have loops that allow information from previous inputs to persist, making them suited for sequences: text, audio, time-series. Their limitation was difficulty learning long-range dependencies, which led to the next entry.
Transformers, introduced in the 2017 Google Brain paper 'Attention Is All You Need' by Vaswani et al., replaced RNNs for most language tasks. Transformers use attention mechanisms to weigh the relevance of every word against every other word in parallel, rather than sequentially. Every major language model in 2026, including OpenAI's GPT series, Google's Gemini, and Anthropic's Claude, is built on transformer architecture.
If you want to understand what powers ChatGPT and Claude specifically, I wrote a deeper explanation in our post on what a large language model is.
Real-World Examples: Where Neural Networks Already Run Your Life
Neural networks are not a future technology. They are running right now, invisibly, inside products you use every day.
ChatGPT, Claude, and Gemini: Large language models built on transformer neural networks with hundreds of billions of parameters. Every word you read in a ChatGPT response was predicted by a neural network choosing from a probability distribution over a vocabulary of 50,000+ tokens.
Face ID on iPhones: Apple's Face ID uses a convolutional neural network trained on depth maps of faces. According to Apple (2017), the probability of a random person unlocking your Face ID is 1 in 1,000,000.
Netflix recommendations: Netflix's recommendation system uses multiple neural network models working together. According to Netflix (2022), over 80% of content watched on the platform is discovered through its recommendation engine.
Google Search: Since 2015, Google has used a neural network called RankBrain (and later MUM, then Gemini-powered Search Generative Experience) to understand search queries. The shift allowed Google to handle queries it had never seen before.
Spotify Discover Weekly: Spotify's collaborative filtering system uses neural networks trained on listening patterns across 600 million users to predict which songs you have not heard yet but are likely to love.
Medical imaging: Convolutional neural networks detect diabetic retinopathy in eye scans with performance comparable to board-certified ophthalmologists, according to a 2016 study in JAMA by Google researchers Gulshan et al.
The neural network software market was valued at approximately USD 41.37 billion in 2025 and is projected to reach USD 52.25 billion in 2026 at a CAGR of 26.3%, according to ResearchAndMarkets (March 2026). The companies dominating this space are Google, Microsoft, NVIDIA, IBM, and Meta.
Neural Networks vs Deep Learning vs Machine Learning
These three terms confuse beginners constantly, and I see them used interchangeably even in professional contexts. Here is the precise relationship.
Machine learning is the broadest category. It refers to any system that learns from data rather than following explicit human-written rules. Decision trees, random forests, linear regression, and neural networks are all types of machine learning.
Neural networks are a specific class of machine learning model inspired by the structure of the brain. They are not the only type of ML model, just the most powerful one for many tasks.
Deep learning is the subset of neural network methods that use deep architectures, meaning networks with many hidden layers (typically more than two). When a network has enough layers to learn increasingly abstract features from raw data, it qualifies as deep learning.
The simplest way to remember it: all deep learning is neural network-based, all neural networks are machine learning, but not all machine learning uses neural networks.
If you want a complete primer on the broader field, our post on what machine learning is covers all of this with the same beginner-first approach.
What Neural Networks Cannot Do
Most AI explainers skip this part. I think it is the most important section in this post.
Neural networks are pattern-matching engines. They are extraordinarily good at finding correlations in large datasets. They are not reasoning engines. They do not understand cause and effect, they recognise associations.
This means: a neural network trained on medical images can outperform a radiologist at detecting certain cancers, but if you change the background colour of the images, performance can collapse. This is called distribution shift, and it is one of the most practical problems in deploying neural networks in the real world.
Neural networks also hallucinate. ChatGPT and Claude produce confidently wrong answers because the model is predicting the most plausible next token, not retrieving verified facts. Our post on why ChatGPT makes up facts explains this in detail.
• Why ChatGPT Makes Up Facts (And What To Do About It)
They are also opaque. Unlike a decision tree where you can trace exactly how a prediction was made, a network with billions of parameters offers no simple explanation for its outputs. This 'black box' problem is an active research area, with teams at Anthropic (who call their approach mechanistic interpretability) and Google DeepMind working on making neural networks more transparent.
And they are data-hungry. Training a useful neural network typically requires large volumes of labelled examples. In domains with limited data, simpler models often outperform deep networks.
My honest take: neural networks are genuinely remarkable. But they are probabilistic, brittle to edge cases, and cannot replace human judgement in high-stakes decisions. They are tools with specific strengths and very real limitations.
Frequently Asked Questions
What is a neural network in simple terms?
A neural network is a machine learning model made up of connected layers of simple processing units (neurons) that learn patterns from data. It learns by repeatedly making predictions, measuring how wrong those predictions are, and adjusting its internal settings to reduce the error. ChatGPT, Face ID, and Netflix recommendations all run on neural networks.
Is ChatGPT a neural network?
Yes. ChatGPT is built on GPT-4 (now GPT-5.5 in 2026), which is a transformer neural network developed by OpenAI with hundreds of billions of parameters. Transformer networks are a type of neural network specifically designed for language tasks. Every response ChatGPT generates is produced by a neural network predicting the most likely next word, one token at a time.
What is the difference between a neural network and deep learning?
Deep learning is a subset of neural network methods that uses architectures with many hidden layers. A network with one or two hidden layers is a neural network but not technically deep learning. Deep learning specifically refers to the multi-layer architectures that can learn increasingly abstract representations from raw data, such as those powering GPT-4 or Google's Gemini 3.5.
How does a neural network learn?
A neural network learns through a cycle called training. It makes a prediction, measures its error with a loss function, and then uses an algorithm called backpropagation to calculate how each weight contributed to the error. It then adjusts those weights using gradient descent. This cycle repeats millions of times until the predictions are accurate enough. The 1986 Nature paper by Rumelhart, Hinton, and Williams formalised the backpropagation algorithm used in virtually all modern neural networks.
What are the 3 types of neural networks?
The most widely used types are convolutional neural networks (CNNs) for images and video, recurrent neural networks (RNNs) for sequences and time-series data, and transformer networks for language and multimodal tasks. Feedforward networks are the simplest type and are used for tabular data. Generative adversarial networks (GANs) are used for data synthesis and image generation.
Do you need maths to understand neural networks?
No. You can understand what neural networks are, how they work conceptually, and when to use them without knowing any maths. If you want to build neural networks from scratch or conduct research, you will eventually need linear algebra, calculus, and probability theory. For everyday use and professional literacy in AI, the conceptual understanding in this post is sufficient.
What are neural networks used for?
Neural networks power image recognition (Google Photos, Face ID), natural language processing (ChatGPT, Claude, Google Translate), speech recognition (Siri, Alexa), recommendation systems (Netflix, Spotify, YouTube), self-driving car perception, medical imaging analysis, fraud detection in banking, and weather forecasting. According to McKinsey's 2025 State of AI report, 88% of organisations regularly use AI in at least one business function, with neural network-based models at the core of most deployments.
What is backpropagation in a neural network?
Backpropagation is the algorithm neural networks use to learn from errors. After the network makes a prediction, backpropagation works backwards from the output to the input, calculating how much each weight in the network contributed to the prediction error. It then adjusts each weight slightly in the direction that reduces that error. The process repeats for every training example until the network's predictions become accurate.
How are neural networks trained?
Neural networks are trained on labelled datasets by repeatedly running examples through the network (forward pass), measuring the prediction error (loss function), using backpropagation to calculate which weights caused the error, and adjusting those weights with gradient descent. Training modern large neural networks requires GPU clusters. GPT-4's training reportedly cost over $100 million in compute, according to estimates published by Epoch AI in 2024.
Recommended Reads
• What Is a Large Language Model? Explained Simply
• What Is Machine Learning? The Clearest Explanation for Beginners
• How Are AI Models Trained? A Plain-English Guide
• What Are AI Embeddings? Explained Simply
• Learn AI From Scratch in 2026: The Complete Beginner Roadmap
AI moves fast. 5 minutes a day keeps you ahead without burning out.
References
• IBM Think -- What Is a Neural Network? (2026)
• AWS -- What is a Neural Network? Artificial Neural Network Explained
• Stanford HAI -- What is a Neural Network?
• Rumelhart, Hinton, Williams -- Learning Representations by Back-propagating Errors, Nature (1986)
• Vaswani et al. -- Attention Is All You Need, Google Brain (2017)
• ResearchAndMarkets -- Neural Network Software Market Report 2026