

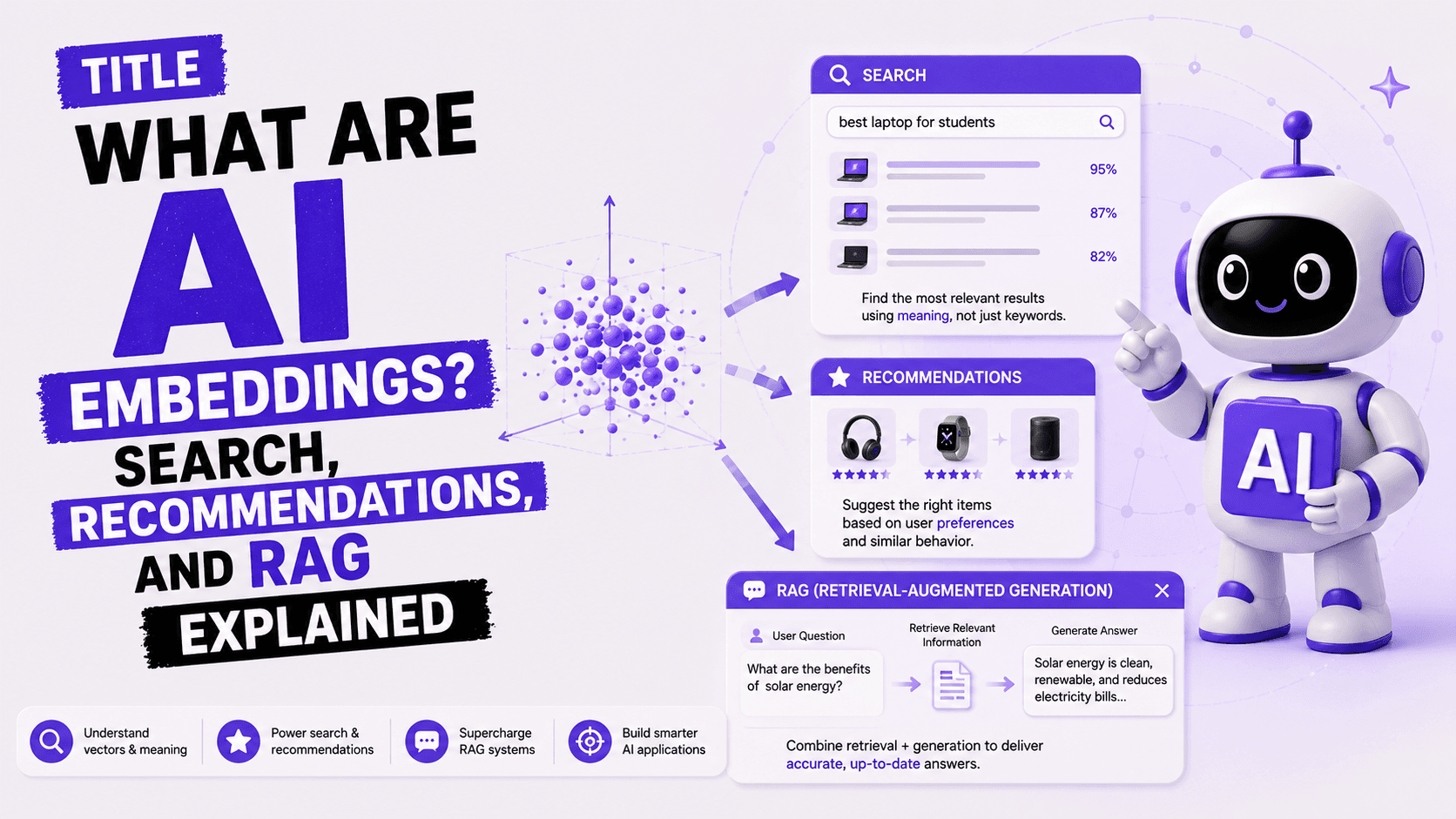
What Are AI Embeddings? Search, Recommendations, and RAG Explained
Spotify has never heard you describe a song. You have never typed "something melancholic, mid-tempo, acoustic, with a female vocalist and minor chords" into a search bar. And yet Discover Weekly finds exactly that kind of song every Monday. No manual tagging. No genre checkbox. Just embeddings.
Embeddings are the single concept that explains why modern AI seems to understand meaning rather than just match keywords. They power semantic search, recommendation engines, the RAG systems behind AI chatbots, and the way large language models process language at all. If you have ever wondered why ChatGPT understands a poorly worded question, or why searching "affordable running shoe" on a shopping site also returns results for "budget jogging trainers" without those words appearing, that is embeddings at work.
This guide explains what they are, how they turn human language into something a machine can reason about, and where you are already relying on them without realising it.
The Core Idea: Turning Meaning Into Numbers
An embedding is a list of numbers that represents the meaning of something. Not just the letters or pixels, but the meaning. A word, a sentence, a document, an image, a user's taste profile, a product listing -- any of these can be converted into an embedding, which is then stored as a high-dimensional vector.
Why numbers? Because computers are excellent at comparing numbers and terrible at comparing meaning. If you ask a computer "which of these two words is more similar to king: queen or banana?", the letters give no useful signal. The embeddings do. The word "queen" produces a vector that sits geometrically close to "king" in embedding space. The word "banana" sits far away. That geometric closeness is the machine's version of semantic similarity.
The formal definition from AWS: embeddings are numerical representations of real-world objects that machine learning systems use to understand complex knowledge domains. They convert real-world objects into mathematical representations that capture inherent properties and relationships, rather than just surface-level features.
A single embedding for a word in a modern model is typically a vector with 768 to 4,096 dimensions. You can think of each dimension as a dial that gets tuned during training to capture some aspect of meaning. No human decides what each dimension encodes -- the model figures out its own geometry of meaning from billions of examples.
One number on its own means nothing. The whole point is the relationship between vectors. Meaning lives in the distances.
How Embeddings Are Created
Embeddings are learned by neural networks during training. The process sounds abstract, but the underlying logic is intuitive: words that appear in similar contexts tend to have similar meanings.
The original breakthrough came from Word2Vec, a model Google published in 2013. The training task was simple: given surrounding words in a sentence, predict the missing word in the middle. To solve this task well, the model had to develop internal representations (embeddings) that captured which words tend to appear together. Words like "doctor," "hospital," and "patient" naturally cluster together. So do "guitar," "chord," and "melody." The model never needed to be told what any of these words meant -- it inferred relationships entirely from patterns of co-occurrence across billions of sentences.
Modern embedding models work on the same principle but at a larger scale and with more sophisticated architectures. Models like OpenAI's text-embedding-3-small and text-embedding-3-large, or Google's text-embedding-004, produce embeddings for entire sentences and paragraphs, not just individual words, which means they capture contextual meaning that changes based on surrounding text. The word "bank" produces a different embedding in "river bank" versus "investment bank" because context is part of the calculation.
Key distinction: embeddings are not hand-crafted features. Nobody designed them. They emerge from training on data, which is exactly what makes them powerful -- and occasionally surprising. The model found its own mathematical representation of meaning.
The Famous Analogy: King, Queen, and What It Reveals
The most cited demonstration of embeddings is the arithmetic: king minus man plus woman approximately equals queen. Subtract the vector for "man" from the vector for "king", add the vector for "woman", and the nearest result in the embedding space is "queen."
This was demonstrated in the original Word2Vec paper by Tomas Mikolov and colleagues at Google in 2013. The model had never been given any information about gender or royalty. It learned the relationship purely from patterns in text -- the fact that king and queen appeared in similar contexts, as did man and woman, and that certain geometric directions in the embedding space corresponded to semantic relationships like gender.
The finding is real but worth being honest about. A 2026 analysis by researcher Mike X Cohen notes that this specific analogy works cleanly, but the pattern does not generalise to all word analogies the way early coverage implied. Embedding vectors in modern language models are also contextual rather than fixed -- the vector for "bank" changes depending on what else is in the text, which means static arithmetic of this kind is an approximation at best.
What the analogy genuinely reveals is the fundamental property of embedding spaces: geometric proximity encodes semantic similarity, and geometric directions can encode semantic relationships. That property is what the entire field of embedding-based AI is built on, even if the geometry is messier in practice than one clean equation suggests.
I find this one of the most interesting facts in all of AI: a model taught to predict missing words in sentences spontaneously develops an internal coordinate system where you can navigate by meaning. Nobody programmed that. It just emerged.
How Embeddings Power Semantic Search
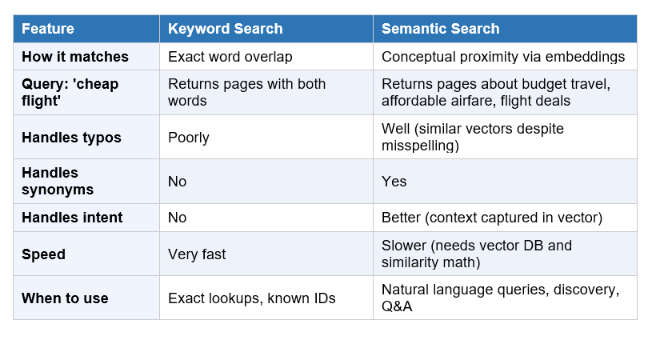
Traditional keyword search works by matching the exact words in your query to the exact words in a document. Type "car repair" and you get pages containing "car" and "repair." Type "automobile maintenance" and you might get nothing, even if the same pages would answer your question.
Semantic search solves this by converting both the query and the documents into embeddings, then finding documents whose embeddings are geometrically close to the query's embedding. The concepts sit near each other in the same vector space, so the system returns "automotive maintenance" pages when you search "car repair" even without shared keywords.
How the similarity is measured
The most common metric is cosine similarity, which measures the angle between two vectors rather than their raw distance. A cosine similarity of 1.0 means the vectors point in exactly the same direction (identical meaning). A score of 0 means they are perpendicular (unrelated). A score of -1 means they point in opposite directions (opposite meaning).
This matters practically because it means semantic search can rank results by how conceptually close they are to the query, not just whether they share words. Searching for "how to deal with burnout" returns results about stress management, work-life balance, and exhaustion even if none of those documents use the word "burnout" explicitly.
Where you already use this: Google Search, Perplexity AI, LinkedIn job recommendations, Notion AI search, GitHub Copilot chat, and every enterprise knowledge base that advertises "AI-powered search" is almost certainly running semantic search on embeddings underneath.
Keyword search vs semantic search at a glance
How Embeddings Power Recommendations
Recommendation systems were using embeddings before the term became widespread in AI discourse. The principle is the same: represent users and items in the same vector space, then find items whose vectors are close to the user's vector.
Spotify's Discover Weekly
Spotify's recommendation system represents each user and each song as a vector in embedding space. Your listening history shapes your user vector. Every song's audio features, lyrical themes, and cultural context shape its song vector. Discover Weekly works by finding song vectors that are close to your user vector in that shared space.
One notable development in Spotify's system (documented in a 2026 analysis from music-tomorrow.com) is multi-dimensional user profiling. Instead of collapsing your entire taste into one vector, the system represents each listener with several long-term interest embeddings -- one capturing lo-fi preferences, another capturing contemporary jazz preferences. A lightweight router then picks the relevant profile based on context like time of day and device. The result is a playlist that serves your Monday morning mood differently from your Friday evening mood, from the same learned embedding data.
Netflix and product recommendations
Netflix blends collaborative filtering with embedding-based approaches. In collaborative filtering, the system finds users with similar viewing vectors to yours and recommends what those similar users watched. The "slow-burn dramas with strong female leads" pattern Netflix identifies isn't coded in by hand -- it emerges from the geometric clustering of users who watch similar content, all represented as points in embedding space.
Amazon product recommendations work on the same principle: each product and each user interaction generates embeddings, and the system finds products whose embeddings sit close to the patterns of your browsing and purchase history.
My take: recommendation systems are where embeddings went from research curiosity to billion-dollar infrastructure. Every major platform that needs to match users to items at scale -- music, video, e-commerce, job listings, dating apps -- is running some version of this geometry.
How Embeddings Power RAG
RAG stands for Retrieval-Augmented Generation. It is the architecture that lets an AI chatbot answer questions from a specific set of documents -- your company wiki, a product manual, a research paper collection -- rather than relying only on what it learned during training.
Embeddings are the mechanism that makes retrieval possible. Without them, the system has no way to find relevant passages from a large document collection quickly. With them, the process takes milliseconds across millions of documents.
The RAG pipeline in four steps
Chunk and embed the documents. Every document in the knowledge base is split into chunks (typically 200-500 tokens each), and each chunk is converted into an embedding using an embedding model. These embeddings are stored in a vector database like Pinecone, Chroma, Weaviate, or pgvector.
Embed the query. When a user asks a question, that question is converted into an embedding using the same model. Same vector space, same geometry.
Retrieve relevant chunks. The system finds the chunks whose embeddings are closest to the query embedding using cosine similarity. These are the passages most likely to contain a relevant answer.
Generate the response. The retrieved chunks are added to the original question and passed to the language model, which generates an answer grounded in that specific retrieved content. The model is not guessing from training data -- it is reasoning over the retrieved passages.
Gartner reports that vector databases will lead database market growth with a 75.3% compound annual growth rate driven by generative AI and RAG adoption. The Vector Database as a Service market grew from $1.62 billion in 2025 to $2.12 billion in 2026. That market exists almost entirely because RAG requires fast, scalable embedding storage and retrieval.
The reason this matters for anyone using enterprise AI tools: every time a chatbot answers based on your company's documents rather than making something up, there is a RAG pipeline with embeddings running underneath it.
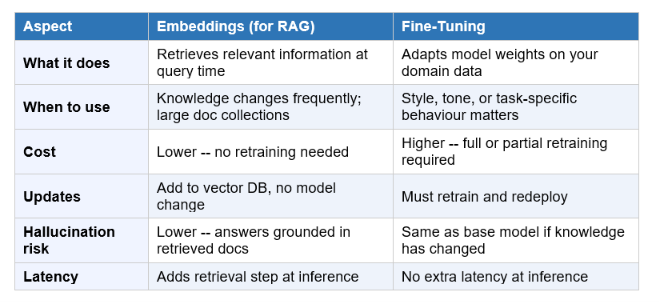
Why RAG beats fine-tuning for knowledge tasks
Fine-tuning bakes knowledge into model weights by retraining on your data. Embeddings-based RAG retrieves knowledge at inference time without changing the model at all. For knowledge that changes frequently -- product pricing, policy documents, recent news -- RAG is far more practical because you can update the document collection without retraining anything. As a 2026 analysis from Atlan puts it: embeddings address retrieval quality; fine-tuning addresses generation quality. They solve different problems.
Embeddings vs Fine-Tuning: Different Tools, Different Jobs
This comparison comes up constantly when teams start building AI systems, so it is worth being explicit about the distinction.
Many production systems use both. The model is fine-tuned for tone and task format (customer support style, medical terminology, legal register), while embeddings handle the retrieval of specific, up-to-date content. They are complementary, not competing.
The Honest Limitations
Embeddings are powerful, but they have real failure modes that practitioners run into constantly.
Vectors from different models are not comparable. OpenAI embeddings and Google embeddings live in different mathematical spaces. You cannot mix vectors from different models in the same vector database and expect meaningful similarity scores. Every document and every query must be embedded using the same model.
Chunking strategy matters enormously. Embedding a 50-page document as a single vector destroys almost all the detail. Standard practice is to chunk documents into 200-500 token segments with some overlap between adjacent chunks. Poor chunking is one of the most common causes of RAG systems giving incorrect answers even when the answer exists in the knowledge base.
Semantic similarity is not the same as factual correctness. A retrieved chunk might be conceptually close to the query without actually containing the right answer. If your retrieval quality is poor, the language model generating the final response has no good material to work with, and the output degrades.
Embeddings can encode bias from training data. Studies have documented that word embeddings trained on internet text inherit the biases present in that text. In the original Word2Vec embeddings, the vector for "doctor" was geometrically closer to male-associated words than female-associated ones, reflecting the corpus rather than reality.
High dimensions have a counterintuitive geometry. In very high-dimensional spaces, distance measures behave strangely compared to human intuition. Most vectors end up roughly equidistant from each other, which can make fine-grained similarity distinctions unreliable in some configurations. This is one reason why approximate nearest-neighbor algorithms like HNSW are used in practice rather than exact search.
None of these make embeddings less useful. They make understanding embeddings more important than just reaching for them by default.
Frequently Asked Questions
Q: What are AI embeddings in simple terms?
An AI embedding is a list of numbers that represents the meaning of something -- a word, sentence, image, or product. Instead of storing text as letters, the model stores it as a vector (an ordered list of numbers) in a mathematical space where similar meanings sit close together. The word "dog" and "puppy" will have vectors near each other in embedding space. "Dog" and "spreadsheet" will be far apart. That geometric proximity is how machines compare meaning rather than just matching characters.
Q: What is the difference between an embedding and a vector?
All embeddings are vectors, but not all vectors are embeddings. A vector is simply an ordered list of numbers. An embedding is specifically a vector produced by a neural network trained to encode semantic meaning, where geometric proximity reflects conceptual similarity. A list of random numbers is a vector. The 1,536-number representation of the word "justice" produced by OpenAI's text-embedding-3-small model, where similar concepts sit geometrically close, is an embedding.
Q: How are embeddings used in RAG systems?
In a RAG pipeline, documents are split into chunks and each chunk is converted into an embedding using an embedding model. These embeddings are stored in a vector database. When a user asks a question, that question is also converted into an embedding, and the system retrieves the chunks whose embeddings are closest to the query. Those chunks are passed to the language model alongside the question, grounding the response in retrieved content rather than model memory. Embeddings make the retrieval step fast and semantically accurate, even across millions of document chunks.
Q: What is cosine similarity and why does it matter for embeddings?
Cosine similarity measures the angle between two vectors in embedding space, returning a score from -1 (opposite directions) to 1 (identical direction). A high cosine similarity means two embeddings are pointing in roughly the same direction in their high-dimensional space, which corresponds to similar meaning. It is the most common way to find the nearest neighbours to a query embedding in a vector database, and it underlies every similarity-based search and recommendation system that uses embeddings.
Q: What is the difference between embeddings and fine-tuning?
Embeddings are used at inference time to represent and retrieve content from an external knowledge base. Fine-tuning adapts a model's internal weights on domain-specific data during training. Embeddings improve what information the model can access. Fine-tuning improves how the model responds given any information. For frequently updated knowledge, embeddings via RAG are more practical because you can update the document collection without retraining. For consistent style, tone, or task format, fine-tuning is more appropriate. Many production AI systems use both.
Q: Do I need to understand embeddings to use AI tools?
For using AI tools like ChatGPT, Claude, or Perplexity, no -- embeddings operate invisibly underneath. For building AI-powered products, particularly anything involving search, recommendations, or chatbots that answer from specific documents, yes. Understanding embeddings is the conceptual foundation for RAG pipelines, vector databases, and semantic search systems. It is also one of the fastest concepts to actually understand, which is probably why it shows up so often in technical onboarding at AI companies.
Q: What is a vector database and how does it store embeddings?
A vector database is a database optimised for storing and querying high-dimensional vectors (embeddings). Unlike traditional databases that use exact matching for queries, vector databases use approximate nearest-neighbour algorithms like HNSW (Hierarchical Navigable Small World) or IVF (Inverted File Index) to find the closest vectors to a query at speed, even across millions of stored embeddings. Popular vector databases in 2026 include Pinecone, Chroma, Weaviate, Qdrant, and pgvector (a PostgreSQL extension). They are the storage layer that makes RAG and semantic search practically deployable at scale.
Q: How does Spotify use embeddings for recommendations?
Spotify represents each user and each song as a vector in a shared embedding space. User vectors are shaped by listening history. Song vectors are shaped by audio features, lyrical themes, and cultural context. Discover Weekly works by finding song vectors geometrically close to your user vector. Spotify's system uses multi-dimensional user profiling, representing each listener with several long-term interest embeddings covering different taste clusters, then routing recommendations based on context like time of day. All of this runs on embedding arithmetic at scale across millions of users and tracks simultaneously.
Recommended Reads
What Is RAG? Retrieval-Augmented Generation Explained Simply
What Is a Vector Database? The AI Memory System Explained for Beginners
What Is Fine-Tuning an AI Model? Plain-English Guide for Beginners
What Is Machine Learning? The Guide That Actually Makes Sense (2026)
Unrot teaches AI in 5 minutes a day. One concept at a time, no jargon, built for people who want to actually understand this stuff rather than just nod along to it. Download the app.
References
Microsoft Azure Architecture Center — Generate Embeddings Phase in RAG
Atlan — What Are Embeddings in AI? How They Power Search and RAG (2026)
music-tomorrow.com — Inside Spotify's Recommendation System: Complete Guide (2026)
Matillion — A Deep Dive Into Embedding and Retrieval-Augmented Generation (RAG)
Mike X Cohen -- King minus Man plus Woman equals Queen: Is It Fake News? (2026)

