


What Is Multimodal AI? How AI Reads Text, Images, and Audio
For most of AI's history, models were like specialists who refused to work together. The text model read text. The image model looked at pictures. The speech model processed audio. You had to move data between them yourself, reformatting, re-uploading, re-prompting each time. It was like having a cardiologist, a radiologist, and a neurologist who would not share a patient's file.
Multimodal AI changes that architecture entirely. A single model can now read your typed question, look at the X-ray you attached, listen to the audio note from the doctor, and synthesise all three into one coherent response. No handoffs. No reformatting. One model, one prompt, every type of data.
GPT-4o, Google Gemini 3, Claude Opus 4, and Apple Intelligence are all multimodal AI systems in 2026. So is the app on your phone that translates a menu by pointing the camera at it. So is the tool your doctor uses to cross-reference an ultrasound image with your blood test results and typed symptoms simultaneously.
Multimodal AI is the shift from AI that reads to AI that perceives. This post explains what that means, how it works under the hood in plain English, and why it represents a structural change in what AI can actually do.
What Is Multimodal AI? The One-Sentence Answer
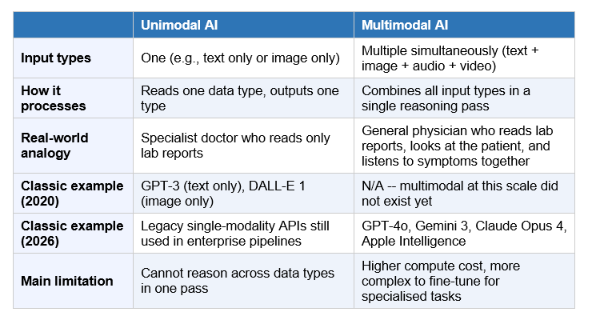
Multimodal AI is an AI system that can process and reason across more than one type of data, typically text, images, audio, and video, within a single unified model rather than as separate disconnected tools.
The word modality simply means data type or channel. Text is one modality. Images are another. Audio is another. Video is another. Structured data (spreadsheets, sensor readings) is another. Traditional AI used single-modality models: one model per data type. Multimodal AI combines multiple modalities into one model that reasons across all of them simultaneously.
The practical consequence is significant. When a doctor types 'what do you see in this scan?' while uploading an X-ray and a patient's written medical history, a multimodal model processes all three at once. It does not look at the scan, summarise it, then read the text. It reasons across text, image, and history together, the same way a clinician does when reviewing all information simultaneously.
According to Roots Analysis (2025), the global multimodal AI market is projected to grow from USD 3.29 billion in 2025 to USD 93.99 billion by 2035, expanding at a CAGR of 39.81%. The multimodal segment commands the highest projected growth rate in generative AI, according to MarketsandMarkets (2025), at 56.6% CAGR.
Unimodal vs Multimodal: Why the Difference Matters
To understand what multimodal AI changes, it helps to understand precisely what it replaces.
A unimodal AI system is a specialist. You give it one type of input, it produces one type of output. A text classification model reads text and returns a label. An image recognition model sees a photo and names what is in it. A speech recognition model converts audio to text. Each of these is highly capable within its single domain. Each is blind to every other domain.
The limitation shows up immediately when real-world problems cross domains, which they almost always do. A student learning chemistry needs an explanation of a structural diagram, but also a verbal description, and also a worked example in text. In a unimodal world, that requires three separate AI calls with manual linking. In a multimodal world, the student uploads the diagram and asks their question in one message.
A logistics manager reviewing a shipping dispute might have a photograph of damaged goods, a typed delivery report, a voice note from the driver, and a PDF contract. A unimodal pipeline requires four separate tools. A multimodal model takes all four simultaneously and reasons across them in one response.
My take: the shift from unimodal to multimodal is not just a convenience upgrade. It removes an entire category of friction between humans and AI systems. The friction of translation, the friction of reformatting, the friction of switching tools. That removal is what makes multimodal AI a structural change rather than a feature addition.
How Multimodal AI Actually Works (No Jargon)
Here is the conceptual picture of what happens inside a multimodal AI model when you send it a photo and a question.
Step 1: Each modality gets its own encoder
Think of an encoder as a translator. Every input type arrives in a format a language model cannot directly read. An image is a grid of pixels. An audio clip is a waveform of pressure values over time. A video is thousands of image frames with audio attached. None of these are text tokens, which is what language models understand natively.
So each modality has its own specialised encoder that converts it into numerical vectors called embeddings. For images, this is usually a Vision Transformer (ViT), which divides the image into small patches (typically 14x14 pixels), embeds each patch as a vector, and adds positional information so the model knows which patch came from where. For audio, a waveform encoder performs an analogous conversion. For video, frames are sampled and each frame is processed like an image.
OpenAI's CLIP model (2021), developed by Alec Radford and colleagues, was the breakthrough that proved image and text representations could be aligned in a shared mathematical space using contrastive learning on internet-scale data. Every modern vision-language model builds on that finding.
Step 2: All encoders project into the same space
Once each modality has been encoded into its own vectors, those vectors need to become comparable to each other so the model can reason across them. This is the projection step. A learned projection layer converts each modality's vectors into the same dimensional space as the language model's text token embeddings.
Think of it like a common currency conversion. British pounds, Indian rupees, and US dollars are all money, but you need to convert them into one unit before you can add them up. The projection layer is that conversion. After it runs, image patches, audio segments, and text tokens all look the same to the underlying language model: they are all just vectors in a shared space.
Step 3: The language model reasons across all modalities at once
Once all inputs have been encoded and projected into the shared embedding space, they are concatenated into a single sequence: [image tokens] [audio tokens] [text tokens] feeding into the transformer together. The transformer's attention mechanism can then attend to any part of the input, regardless of which modality it came from. A text token about 'the red structure on the left' can attend to the image patch that represents exactly that structure.
This joint attention across modalities is what gives multimodal AI its reasoning power. The model is not looking at the image and then reading the text in sequence. It is processing all modalities together, allowing every piece of information to influence every other piece in a single forward pass.
The 3 Fusion Methods: How Models Combine Different Inputs
Not all multimodal models combine inputs the same way. Three architectural approaches dominate the field, each with different trade-offs.
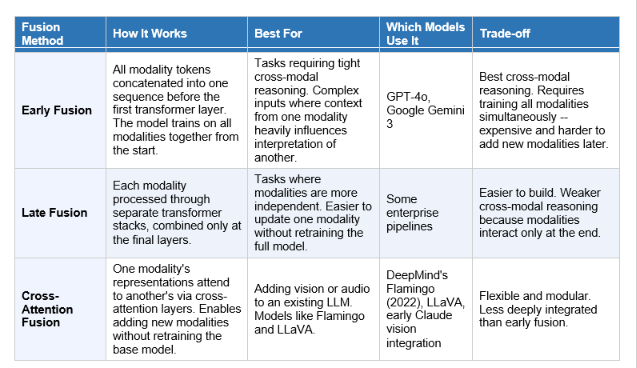
In 2026, early fusion has become the dominant architecture for frontier models because the superior cross-modal reasoning it enables outweighs the training cost. Google Gemini 3 was designed as a natively multimodal model from the ground up, with text, image, and audio tokens processed jointly at every layer. GPT-4o, released by OpenAI in May 2024, was a similar architectural step: a model that natively integrates multimodal encoders into its dense transformer stack rather than bolting them on afterwards.
Open-source models have caught up significantly. InternVL3.5-78B (August 2025, OpenGVLab) matches GPT-4o on several benchmarks including MMIU (55.8 vs GPT-4o's 55.7) using SigLIP as its vision encoder and InternLM as the language backbone, making on-premise multimodal deployment genuinely viable as of 2026.
The Major Multimodal AI Models in 2026
The frontier of multimodal AI moved fast between 2023 and 2026. Here is where each major model stands.
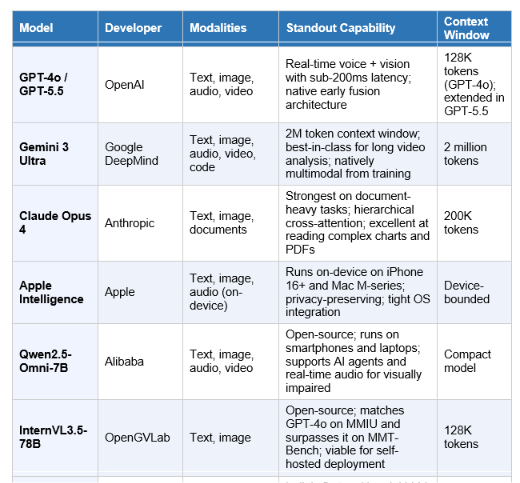
A pattern worth noting: as of June 2026, Claude has become the fastest-growing major AI chatbot by web visits, up 855% year-over-year and 228% in a single quarter (February to May 2026), according to Momentic/Similarweb data. A significant portion of that growth is enterprise customers who value Claude's document and image analysis capabilities in high-stakes professional contexts.
Real-World Examples: Where Multimodal AI Is Already Running
Multimodal AI is not coming. It is already embedded in products billions of people use. Here are the most significant deployments.
Healthcare: Reading multiple data types simultaneously
Medical diagnosis is inherently multimodal. A clinician reads lab reports (text), interprets imaging (visual), listens to a patient describe symptoms (audio), and correlates historical records (documents). AI systems that can reason across all four simultaneously are dramatically more useful than single-modality tools.
Niramai, a Bengaluru-based startup, uses a multimodal AI system combining high-resolution FLIR thermal sensor data (image) with patient history text to screen for breast cancer. The system has screened over 280,000 women across 200+ hospitals and diagnostic centres in 30 Indian cities as of Q2 2026, at a cost of approximately Rs 1,200 per scan, one-fifth the cost of a digital mammogram, and is particularly valuable in rural areas where mammography equipment is scarce.
According to a 2026 review published in Current Opinion in Biomedical Engineering (Demrozi and Farmanbar), multimodal AI integrating medical imaging, electronic health records, wearable sensor data, and genomic sequencing is enabling a shift from reactive to predictive healthcare, reducing clinician burnout and accelerating diagnostic turnaround.
Education: Explaining concepts across formats
BYJU'S and other Indian edtech platforms have deployed multimodal AI that allows students to photograph a maths problem, speak their confusion aloud, and receive both a text explanation and a visual step-by-step diagram in response. A student does not need to type. They do not need to describe the problem in words. They hold up their phone. The model sees the equation, hears the question, and teaches.
Byju's Maths Tutor AI, deployed from FY2026, offers 54,000 adaptive practice problems and 3D visual explainers in English, Hindi, and 10 regional languages, drawing on data from 20 million Indian learners to personalise difficulty level. The system's multimodal capability (it reads handwritten student work submitted via camera) is central to its tutoring loop.
Productivity and work
Google Workspace's Gemini integration allows users to highlight a section of a spreadsheet, paste a photo of a handwritten note, and ask Gemini to reconcile the two in a single prompt. Microsoft Copilot in Word can read a PDF attachment, a typed brief, and a PowerPoint outline simultaneously to draft a combined document. These are multimodal workflows that would have required at least three separate AI calls and manual reconciliation in 2023.
Accessibility
Alibaba's Qwen2.5-Omni-7B (March 2025) supports real-time audio guidance for visually impaired users: a user points their smartphone camera at an environment, the model sees what the camera sees, and provides a real-time audio description of what is in front of them. This runs on-device on a smartphone, without cloud connectivity. For a country with 8 million registered blind individuals in India alone (WHO, 2023), multimodal AI running on a standard Android device is a genuine accessibility leap.
Autonomous agents
The most consequential application of multimodal AI in the near term is agentic AI systems that can operate software interfaces visually. An AI agent with only text access can use APIs and read text output. An agent with vision can take a screenshot of any application, identify interface elements by appearance (buttons, menus, input fields), and interact with them as a human would. This removes the API requirement entirely, making automation possible for any software, including legacy systems with no API.
Our post on what agentic AI is covers how AI agents work and why multimodal perception is the capability that unlocks most of their real-world power.
Multimodal AI vs Generative AI vs LLMs: Clearing Up the Confusion
These three terms are used interchangeably and that is almost always imprecise. Here is the exact relationship.
A large language model (LLM) is a transformer-based neural network trained primarily on text to understand and generate natural language. It is unimodal by default: one input type, one output type. GPT-3, Llama 2 in its base form, and BERT are LLMs.
Generative AI is broader: any AI system that creates new content in response to a prompt. Generative AI includes LLMs (which generate text), diffusion models (which generate images), audio synthesis models (which generate music or speech), and video generation models. Generative AI can be unimodal or multimodal.
Multimodal AI refers specifically to systems that process more than one type of input and reason across them. Multimodal AI can be generative (GPT-4o generates text after processing an image input) or non-generative (an autonomous driving system that processes camera images, LiDAR point clouds, and map data to make navigation decisions without generating any text).

The simplest way to keep these straight: LLMs are a type of generative AI. Multimodal AI is a capability that LLMs (and other AI systems) can have or not have. GPT-4o is an LLM with multimodal capability. GPT-3 was an LLM without it.
Our post on what a large language model is covers LLMs in depth, including the transformer architecture that both LLMs and multimodal models share.
What Multimodal AI Still Cannot Do
Multimodal AI is genuinely impressive. It is also genuinely limited in ways that matter for real deployment.
Cross-modal hallucination is worse than single-modality hallucination. When a model combines image, audio, and text, it has more ways to confuse inputs and generate confident but wrong outputs. A model that correctly reads a medical report and correctly describes an X-ray in isolation may combine them incorrectly when asked to draw conclusions from both simultaneously. Research from 2026 shows that multimodal models hallucinate more frequently on tasks requiring tight cross-modal reasoning than on single-modality tasks.
Audio quality is the weakest modality in most current models. Text and image understanding have benefited from years of benchmark development and large training datasets. Audio understanding, particularly for accented speech, regional languages, and noisy real-world environments, lags behind. A model that processes clear English audio well may fail substantially on Tamil or Marathi audio from a noisy location.
Long video understanding remains hard. Gemini 3's 2 million token context window is the current frontier for video analysis, but processing a full feature-length film at full quality requires either significant compression (losing detail) or enormous compute cost. Most multimodal video tools sample frames rather than processing continuously, which means they can miss events that happen between sampled frames.
Proprietary multimodal models are expensive to run at scale. GPT-4o API calls with image inputs cost significantly more than text-only calls. For startups building in India where compute budgets are constrained, this creates a real barrier. Open-source alternatives like InternVL3.5-78B and Qwen2.5-Omni-7B are closing the performance gap but still require substantial GPU infrastructure to run at production scale.
My honest take: multimodal AI is the right direction for AI development. Humans naturally integrate information across senses, and AI that can do the same is genuinely more useful. But the hype around it in 2026 often obscures significant limitations. For anyone building with multimodal AI, understanding where each modality is strong and where it fails is essential engineering knowledge, not a footnote.
Multimodal AI in India: Why This Matters Specifically Here
Multimodal AI is not equally important everywhere. In India specifically, it is more important than in most other markets for a structural reason: 1.4 billion people speak dozens of languages, many of which have limited text-based digital content but rich oral and visual traditions.
Text-only AI disadvantages non-English speakers disproportionately. A farmer in Rajasthan who speaks Rajasthani and has limited literacy in standardised Hindi cannot effectively use a text-first AI assistant. A multimodal AI that accepts voice input in local languages, processes a photo of a crop disease, and responds with both spoken and visual output in the local language is immediately practical where a text-only AI is not.
The Indian government recognised this explicitly. On June 2, 2025, the Indian government launched BharatGen AI, India's first multimodal large language model built to work across all 22 scheduled Indian languages. Developed at IIT Bombay under the IndiaAI Mission with over Rs 10,300 crore in funding, BharatGen integrates text, speech, and image processing to make AI deeply rooted in Indian linguistic and cultural contexts. The stated goal is to transform healthcare, education, and governance delivery for populations that existing English-first AI systems do not serve.
Bhashini, India's national multilingual AI platform, signed an MoU with multiple state governments in June 2025 to deploy multimodal voice-and-text AI for citizen service delivery. A resident can now speak their query in Odia to a government portal that converts speech to text, processes the request, and responds in both text and synthesised Odia speech.
At the AI Impact Summit 2026 in New Delhi, Prime Minister Modi explicitly emphasised that India should develop AI systems rooted in its own knowledge traditions and regional languages rather than replicating Western AI pathways. The New Delhi Declaration 2026 placed multilingual multimodal AI at the centre of India's AI agenda, with specific emphasis on accessibility for underserved communities.
For Indian students and professionals reading this: multimodal AI is not just a Silicon Valley feature update. It is the specific capability that will determine whether AI is useful for 400 million Indians who primarily communicate in regional languages, or whether it remains a tool for English-speaking urban elites. That stakes framing is why India has invested nationally in multimodal AI infrastructure at a scale few other countries have matched.
If you want to learn how to use these tools practically, our post on prompt engineering covers how to structure multimodal prompts effectively across image, audio, and text inputs.
Frequently Asked Questions
What is multimodal AI in simple terms?
Multimodal AI is an AI system that can process and understand more than one type of data at the same time, such as text, images, audio, and video, within a single unified model. Instead of needing separate tools for each type of input, a multimodal model handles all of them together and reasons across them simultaneously. GPT-4o, Google Gemini 3, and Claude Opus 4 are all multimodal AI systems. The global multimodal AI market is projected to grow from USD 3.29 billion in 2025 to USD 93.99 billion by 2035 at a CAGR of 39.81%, according to Roots Analysis (2025).
How does multimodal AI work?
Multimodal AI works by converting each input type into a common numerical format called embeddings, then reasoning across all of them together in a single transformer model. Each data type has its own encoder: a Vision Transformer (ViT) converts image patches into vectors, an audio encoder converts waveforms into vectors, and the text tokenizer converts words into vectors. A projection layer maps all of these into the same dimensional space, and then the transformer's attention mechanism can reason across text, image, and audio tokens simultaneously. The 2021 CLIP model from OpenAI, developed by Alec Radford and colleagues, was the breakthrough that proved image and text representations could be aligned in this shared space.
What is an example of multimodal AI?
GPT-4o is the most widely used example: it processes text, images, audio, and video in one model with real-time response capability. Google Lens uses multimodal AI to identify objects, translate text in photos, and find similar products when you point your camera at something. Apple's Live Text feature (iOS) reads text in photos using on-device multimodal AI. India's BharatGen AI, launched June 2, 2025 at IIT Bombay, is a multimodal model spanning 22 Indian languages that integrates text, speech, and image for healthcare and education applications. Niramai's breast cancer screening system in India combines thermal imaging (visual) with patient history text to detect tumours at 200+ hospitals.
Is ChatGPT multimodal?
Yes. ChatGPT running on GPT-4o (and GPT-5.5 in 2026) is multimodal. It can accept text, images, audio, and video as inputs and generate text (and audio) as output. Earlier versions of ChatGPT, including those running on GPT-3 and GPT-3.5, were text-only, meaning they were unimodal. The shift to multimodal capability happened with GPT-4V (September 2023, which added image input) and was fully integrated with GPT-4o (May 2024, which unified text, image, and audio in a single model with real-time processing).
What is the difference between multimodal AI and LLM?
An LLM (large language model) is a transformer-based neural network trained primarily on text. It is text-in, text-out by default. A multimodal AI is any AI system that processes more than one type of data. A multimodal LLM is a language model that has been extended with modality encoders for images, audio, or video, so it can accept and reason across multiple input types while still generating text output. GPT-3 was a unimodal LLM. GPT-4o is a multimodal LLM. Not all multimodal AI is an LLM: an autonomous vehicle's perception system is multimodal AI that does not use an LLM at its core.
What is the difference between multimodal AI and generative AI?
Generative AI is any AI that creates new content in response to a prompt, including text, images, audio, video, or code. Multimodal AI refers specifically to systems that process multiple types of input simultaneously. These categories overlap but are not identical. DALL-E 3 is generative AI but is unimodal: it takes text input and produces image output. GPT-4o is both generative AI and multimodal: it takes text and image input and generates text and audio output. An autonomous vehicle's perception system is multimodal AI but is not generative: it processes camera images, LiDAR, and map data to make navigation decisions without creating any content.
Which AI model is the best for multimodal tasks in 2026?
It depends on the task. For real-time voice and vision with low latency, GPT-4o leads with sub-200ms response times. For long video analysis and documents that require very long context, Google Gemini 3's 2 million token context window is currently unmatched. For document-heavy professional tasks involving complex PDFs, charts, and spreadsheets, Claude Opus 4 consistently ranks highest in enterprise evaluations. For open-source self-hosted deployment, InternVL3.5-78B (August 2025, OpenGVLab) matches GPT-4o on several benchmarks and runs on-premise. For multilingual Indian-language tasks, BharatGen AI is specifically designed for 22 Indian languages across text, speech, and image.
What are the limitations of multimodal AI?
Multimodal AI has four significant limitations in 2026. First, cross-modal hallucination: models can generate confident wrong outputs when combining information across modalities, and this is more common than hallucination in single-modality tasks. Second, audio quality gaps: most models handle clear English audio well but degrade significantly on accented, regional, or noisy audio. Third, long video limitations: even 2 million token context windows require frame sampling for long videos, meaning events between sampled frames can be missed. Fourth, cost: multimodal API calls with image inputs cost substantially more than text-only calls, creating barriers for cost-sensitive deployment in emerging markets.
Recommended Reads
• What Is Generative AI? The Beginner's Guide
• What Is a Large Language Model?
• What Is a Neural Network? Plain-English
• What Is NLP? Natural Language Processing
• What Is Agentic AI? How AI Systems Are Learning
AI that can only read was useful. AI that can see, hear, and read together is something fundamentally different.
References
• Roots Analysis - Multimodal AI Market Size
• MarketsandMarkets - Generative AI Market
• Analytics Insight - 2025 Year in Review
• Business Standard - Why Multilingual
• Let's Data Science - How Multimodal AI
• MyEngineeringPath - Multimodal AI Guide
• Demrozi and Farmanbar - Multimodal AI
• ExplainX.ai - What Is Multimodal AI?

